腾讯QQ大数据:Quicksilver快数据处理系统
作者:CQITer小编 时间:2018-08-30 21:22
背景
随着神盾推荐业务场景的不断深入,传统的离线训练+线上计算的模式可以说是推荐系统1代框架,已经不能完全满足部分业务场景的需求,如短视频、文本等快消费场景。下面先简单介绍下传统模式以及其在不断变化的场景需求中的不足点。
传统模式简单介绍
传统模式下,整个推荐流程粗略可分为,数据上报、样本及特征构造,离线训练评测,线上实时计算,abtest等。
• 优点:
系统架构简单
普适性较强,能满足大多数业务场景。
• 缺点:
数据及时性不够。
模型实时性不强。
下面举一个简单例子,来说明这样的问题:

小明同学在微视上看了一个视频,那么在推荐场景下,可能会遇到以上四类需求,并且每种需求对于数据的实时性要求并不一样。从推荐系统功能来看,可以概括为已阅实时过滤、用户行为实时反馈、物品池子更新等。所以如果要满足业务需求,从代码层面来看,这样的需求并不复杂,但是从架构层面或者可扩展性来说,神盾作为一个面向不同业务的通用推荐平台,就需要提供一个能满足大多数业务,对于快速据消费的通用平台。
针对不同业务、不同场景需求,神盾希望构建一个快数据处理系统,旨在满足更多业务场景的快速据消费场景。
任何系统的搭建及开发离不开特定的业务场景需求调查,神盾根据多年业务经验,收集归纳了相关快数据处理的相关需求,具体如下:

我们深入调研、讨论,结合业界实践以及神盾的实际情况,总结为两类系统需求:
• 1、 近线系统。满足业务对于物品、特征、及其他数据类服务的准实时更新。
• 2、 在线学习。满足业务对于模型的准实时迭代更新。
基于以上调研,神盾推出Quicksilver(快数据计算)系统,解决推荐场景下快数据计算及更新问题。
系统设计Quicksilver系统是一个集近线及在线学习能力为一体的通用架构系统,我们设计之初,从收、算、存、用四个维度来进行设计,如下:
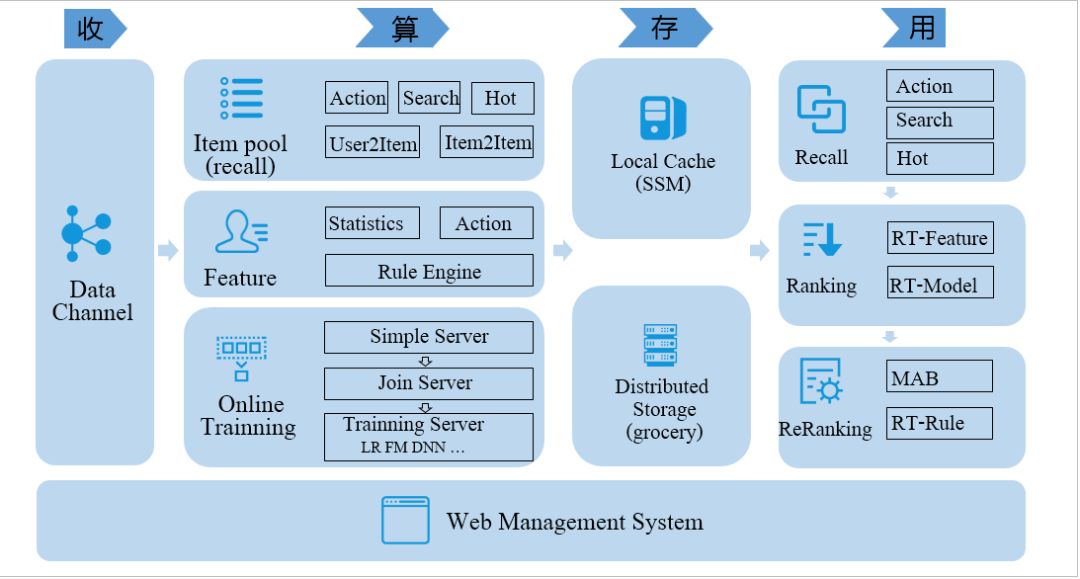
• 收:数据的收集。目前主要支持基于DC、TDBank数据通道上报。
• 算:计算层。针对不同的数据类型,定义不同的计算模块。不同的计算模块,采样不同的技术方案来实现。例如对于物品池子此类分钟级更新要求的数据,我们采用sparkstreaming,而对于用户行为实时反馈等类数据,我们采用spp实时处理类服务器框架。设计中屏蔽掉用户对于底层实现的细节。
• 存:存储层。针对不同的数据规模及访问频率,神盾采用不同的存储介质来满足数据存储的要求及对线上服务延迟的要求。例如对于物品类特征、池子类数据,神盾采用自研的SSM系统,而对于用户类特征,数据量较大、存储访问实时性要求也较高,我们选型为公司的grocery存储组件。
• 用:使用对接层。通过Quicksilver计算得到的数据,我们均通过神盾产品化来配置管理,降低对于数据使用的门槛,最终可以通过配置,直接与线上的召回、精排、重排、规则等计算单元进行打通使用。
架构实现
以上为Quicksilver整体架构实现图,主要分为近线系统及在线学习系统。下面详细介绍。
近线系统
近线系统主要为了满足以下几类细分需求:
• 实时召回:
Quicksilver处理物料,经过各通道后到线上 (要求秒级,实际分钟级)
• 实时因子:
Quicksilver统计计算,经过各通道后到线上(分钟级)
• 实时特征:
统计型(物料、行为、场景):Quicksilver计算,经过各通道后到线上(分钟级)
实时特征(用户):实时特征构造引擎构造,构造后直接对接线上(秒级)
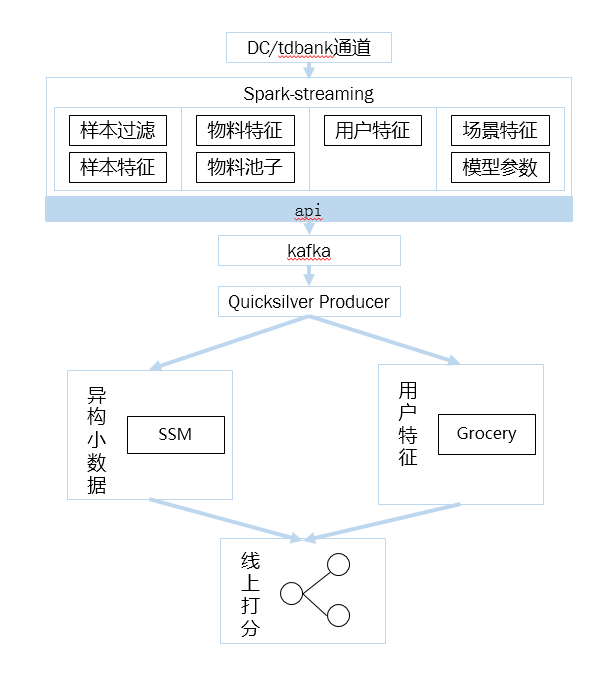
于是,在选型上,我们针对不同的数据计算模式,选择不同的计算平台,对于统计类型数据,我们选择sparkstreaming来作为我们的计算平台,对于实时性要求较高的数据,如实时反馈类,我们采用spp来进行平台型封装。
数据批处理



;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}