Apache Flink 漫谈系列(13) - Table API 概述
作者:CQITer小编 时间:2019-01-03 21:43
一、什么是Table API
在《Apache Flink 漫谈系列(08) - SQL概览》中我们概要的向大家介绍了什么是好SQL,SQL和Table API是Apache Flink中的同一层次的API抽象,如下图所示:
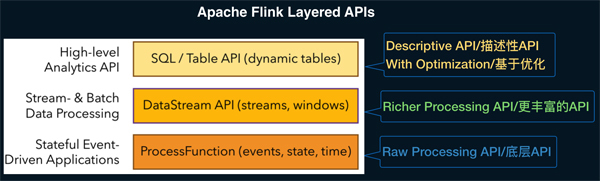
Apache Flink 针对不同的用户场景提供了三层用户API,最下层ProcessFunction API可以对State,Timer等复杂机制进行有效的控制,但用户使用的便捷性很弱,也就是说即使很简单统计逻辑,也要较多的代码开发。第二层DataStream API对窗口,聚合等算子进行了封装,用户的便捷性有所增强。最上层是SQL/Table API,Table API是Apache Flink中的声明式,可被查询优化器优化的高级分析API。
二、Table API的特点
Table API和SQL都是Apache Flink中最高层的分析API,SQL所具备的特点Table API也都具有,如下:
声明式 - 用户只关心做什么,不用关心怎么做;
高性能 - 支持查询优化,可以获取最好的执行性能;
流批统一 - 相同的统计逻辑,既可以流模式运行,也可以批模式运行;
标准稳定 - 语义遵循SQL标准,语法语义明确,不易变动。
当然除了SQL的特性,因为Table API是在Flink中专门设计的,所以Table API还具有自身的特点:
表达方式的扩展性 - 在Flink中可以为Table API开发很多便捷性功能,如:Row.flatten(), map/flatMap 等
功能的扩展性 - 在Flink中可以为Table API扩展更多的功能,如:Iteration,flatAggregate 等新功能
编译检查 - Table API支持java和scala语言开发,支持IDE中进行编译检查。
说明:上面说的map/flatMap/flatAggregate都是Apache Flink 社区 FLIP-29 中规划的新功能。
三、HelloWorld
在介绍Table API所有算子之前我们先编写一个简单的HelloWorld来直观了解如何进行Table API的开发。
1. Maven 依赖
在pom文件中增加如下配置,本篇以flink-1.7.0功能为准进行后续介绍。
<properties>
<table.version>1.7.0</table.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_2.11</artifactId>
<version>${table.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${table.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${table.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${table.version}</version>
</dependency>
</dependencies>
2. 程序结构
在编写第一Flink Table API job之前我们先简单了解一下Flink Table API job的结构,如下图所示:
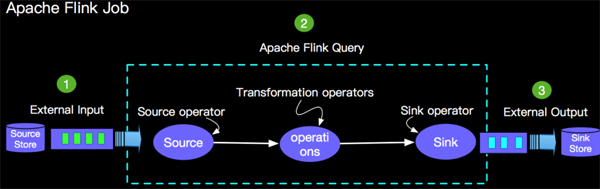
外部数据源,比如Kafka, Rabbitmq, CSV 等等;
查询计算逻辑,比如最简单的数据导入select,双流Join,Window Aggregate 等;
外部结果存储,比如Kafka,Cassandra,CSV等。
说明:1和3 在Apache Flink中统称为Connector。
3. 主程序
我们以一个统计单词数量的业务场景,编写第一个HelloWorld程序。
根据上面Flink job基本结构介绍,要Table API完成WordCount的计算需求,我们需要完成三部分代码:
TableSoruce Code - 用于创建数据源的代码
Table API Query - 用于进行word count统计的Table API 查询逻辑
TableSink Code - 用于保存word count计算结果的结果表代码
(1) 运行模式选择
一个job我们要选择是Stream方式运行还是Batch模式运行,所以任何统计job的第一步是进行运行模式选择,如下我们选择Stream方式运行。
// Stream运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tEnv = TableEnvironment.getTableEnvironment(env)
(2) 构建测试Source
我们用最简单的构建Source方式进行本次测试,代码如下:
// 测试数据



 - Table API 概述','https://cqiter.tag.org.cn/images/defaultpic.gif','https://cqiter.tag.org.cn');){kind=link}
 - Table API 概述','https://cqiter.tag.org.cn/images/defaultpic.gif','https://cqiter.tag.org.cn','在《Apache Flink 漫谈系列(08) - SQL概览》中我们概要的向大家介绍了什么是好SQL,SQL和Table API是Apache Flink中的同一层次的');){kind=link}
 - Table API 概述','https://cqiter.tag.org.cn/images/defaultpic.gif','https://cqiter.tag.org.cn');){kind=link}
 - Table API 概述','https://cqiter.tag.org.cn/images/defaultpic.gif','https://cqiter.tag.org.cn','在《Apache Flink 漫谈系列(08) - SQL概览》中我们概要的向大家介绍了什么是好SQL,SQL和Table API是Apache Flink中的同一层次的');){kind=link}