Apache Flink 漫谈系列 - 持续查询(Continuous Queries)
作者:媒体转发 时间:2018-11-07 21:00
我们知道在流计算场景中,数据是源源不断的流入的,数据流永远不会结束,那么计算就永远不会结束,如果计算永远不会结束的话,那么计算结果何时输出呢?本篇将介绍Apache Flink利用持续查询来对流计算结果进行持续输出的实现原理。
二、数据管理
在介绍持续查询之前,我们先看看Apache Flink对数据的管理和传统数据库对数据管理的区别,以MySQL为例,如下图:

如上图所示传统数据库是数据存储和查询计算于一体的架构管理方式,这个很明显,oracle数据库不可能管理MySQL数据库数据,反之亦然,每种数据库厂商都有自己的数据库管理和存储的方式,各自有特有的实现。在这点上Apache Flink海纳百川(也有corner case),将data store 进行抽象,分为source(读) 和 sink(写)两种类型接口,然后结合不同存储的特点提供常用数据存储的内置实现,当然也支持用户自定义的实现。
那么在宏观设计上Apache Flink与传统数据库一样都可以对数据表进行SQL查询,并将产出的结果写入到数据存储里面,那么Apache Flink上面的SQL查询和传统数据库查询的区别是什么呢?Apache Flink又是如何做到求同(语义相同)存异(实现机制不同),完美支持ANSI-SQL的呢?
三、静态查询
传统数据库中对表(比如 flink_tab,有user和clicks两列,user主键)的一个查询SQL(select * from flink_tab)在数据量允许的情况下,会立刻返回表中的所有数据,在查询结果显示之后,对数据库表flink_tab的DML操作将与执行的SQL无关了。也就是说传统数据库下面对表的查询是静态查询,将计算的最终查询的结果立即输出,如下:
select * from flink_tab;
+----+------+--------+
| id | user | clicks |
+----+------+--------+
| 1 | Mary | 1 |
+----+------+--------+
1 row in set (0.00 sec)
当我执行完上面的查询,查询结果立即返回,上面情况告诉我们表 flink_tab里面只有一条记录,id=1,user=Mary,clicks=1; 这样传统数据库表的一条查询语句就完全结束了。传统数据库表在查询那一刻我们这里叫Static table,是指在查询的那一刻数据库表的内容不再变化了,查询进行一次计算完成之后表的变化也与本次查询无关了,我们将在Static Table 上面的查询叫做静态查询。
四、持续查询
什么是连续查询呢?连续查询发生在流计算上面,在 《Apache Flink 漫谈系列 - 流表对偶(duality)性》 中我们提到过Dynamic Table,连续查询是作用在Dynamic table上面的,永远不会结束的,随着表内容的变化计算在不断的进行着...
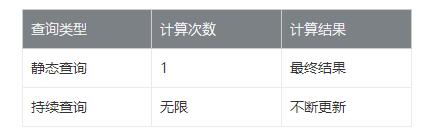
五、静态/持续查询特点
静态查询和持续查询的特点就是《Apache Flink 漫谈系列 - 流表对偶(duality)性》中所提到的批与流的计算特点,批一次查询返回一个计算结果就结束查询,流一次查询不断修正计算结果,查询永远不结束,表格示意如下:
六、静态/持续查询关系
接下来我们以flink_tab表实际操作为例,体验一下静态查询与持续查询的关系。假如我们对flink_tab表再进行一条增加和一次更新操作,如下:
MySQL> insert into flink_tab(user, clicks) values ('Bob', 1);
Query OK, 1 row affected (0.08 sec)
MySQL> update flink_tab set clicks=2 where user='Mary';
Query OK, 1 row affected (0.06 sec)
这时候我们再进行查询 select * from flink_tab ,结果如下:
MySQL> select * from flink_tab;
+----+------+--------+
| id | user | clicks |
+----+------+--------+
| 1 | Mary | 2 |
| 2 | Bob | 1 |
+----+------+--------+
2 rows in set (0.00 sec)



','https://cqiter.tag.org.cn/images/defaultpic.gif','https://cqiter.tag.org.cn');){kind=link}
','https://cqiter.tag.org.cn/images/defaultpic.gif','https://cqiter.tag.org.cn','我们知道在流计算场景中,数据是源源不断的流入的,数据流永远不会结束,那么计算就永远不会结束,如果计算永');){kind=link}
','https://cqiter.tag.org.cn/images/defaultpic.gif','https://cqiter.tag.org.cn');){kind=link}
','https://cqiter.tag.org.cn/images/defaultpic.gif','https://cqiter.tag.org.cn','我们知道在流计算场景中,数据是源源不断的流入的,数据流永远不会结束,那么计算就永远不会结束,如果计算永');){kind=link}