什么是自注意力机制?
作者:CQITer小编 时间:2018-08-27 01:31
参与:Geek AI、刘晓坤
注意力机制模仿了生物观察行为的内部过程,即一种将内部经验和外部感觉对齐从而增加部分区域的观察精细度的机制。注意力机制可以快速提取稀疏数据的重要特征,因而被广泛用于自然语言处理任务,特别是机器翻译。而自注意力机制是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。本文通过文本情感分析的案例,解释了自注意力机制如何应用于稀疏文本的单词对表征加权,并有效提高模型效率。
目前有许多句子表征的方法。本文作者之前的博文中已经讨论了 5 中不同的基于单词表征的句子表征方法。想要了解更多这方面的内容,你可以访问以下链接:
https://kionkim.github.io/(尽管其中大多数资料是韩文)
句子表征
在文本分类问题中,仅仅对句子中的词嵌入求平均的做法就能取得良好的效果。而文本分类实际上是一个相对容易和简单的任务,它不需要从语义的角度理解句子的意义,只需要对单词进行计数就足够了。例如,对情感分析来说,算法需要对与积极或消极情绪有重要关系的单词进行计数,而不用关心其位置和具体意义为何。当然,这样的算法应该学习到单词本身的情感。
循环神经网络
为了更好地理解句子,我们应该更加关注单词的顺序。为了做到这一点,循环神经网络可以从一系列具有以下的隐藏状态的输入单词(token)中抽取出相关信息。
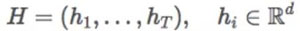
当我们使用这些信息时,我们通常只使用最后一个时间步的隐藏状态。然而,想要从仅仅存储在一个小规模向量中的句子表达出所有的信息并不是一件容易的事情。
卷积神经网络
借鉴于 n-gram 技术的思路,卷积神经网络(CNN)可以围绕我们感兴趣的单词归纳局部信息。为此,我们可以应用如下图所示的一维卷积。当然,下面仅仅给出了一个例子,我们也可以尝试其它不同的架构。

大小为 3 的一维卷积核扫描我们想要归纳信息的位置周围的单词。为此,我们必须使用大小为 1 的填充值(padding),从而使过滤后的长度保持与原始长度 T 相同。除此之外,输出通道的数量是 c_1。
接着,我们将另一个过滤器应用于特征图,最终将输入的规模转化为 c_2*T。这一系列的过程实在模仿人类阅读句子的方式,首先理解 3 个单词的含义,然后将它们综合考虑来理解更高层次的概念。作为一种衍生技术,我们可以利用在深度学习框架中实现的优化好的卷积神经网络算法来达到更快的运算速度。
关系网络
单词对可能会为我们提供关于句子的更清楚的信息。实际情况中,某个单词往往可能会根据其不同的用法而拥有不同的含义。例如,「I like」中的单词「like」(喜欢)和它在「like this」(像... 一样)中的含义是不同的。如果我们将「I」和「like」一同考虑,而不是将「like」和「this」放在一起考虑,我们可以更加清楚地领会到句子的感情。这绝对是一种积极的信号。Skip gram 是一种从单词对中检索信息的技术,它并不要求单词对中的单词紧紧相邻。正如单词「skip」所暗示的那样,它允许这些单词之间有间隔。

正如你在上图中所看到的,一对单词被输入到函数 f(⋅) 中,从而提取出它们之间的关系。对于某个特定的位置 t,有 T-1 对单词被归纳,而我们通过求和或平均或任意其它相关的技术对句子进行表征。当我们具体实现这个算法时,我们会对包括当前单词本身的 T 对单词进行这样的计算。
需要一种折衷方法
我们可以将这三种不同的方法写作同一个下面的通用形式:
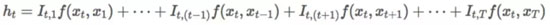
当所有的 I_{t,⋅} 为 1 时,通用形式说明任何「skip bigram」对于模型的贡献是均匀的。
对于 RNN 来说,我们忽略单词 x_t 之后的所有信息,因此上述方程可以化简为:
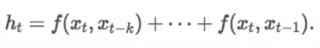
对于双向 RNN 来说,我们可以考虑从 x_T 到 x_t 的后向关系。
另一方面,CNN 只围绕我们感兴趣的单词浏览信息,如果我们只关心单词 x_t 前后的 k 个单词,通用的公式可以被重新排列为:
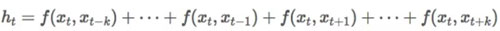



;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}