突破LLM极限!DeepSeek-OCR竟能用一张图压缩百万字文档,你敢信?
作者:佚名 时间:2025-11-15 20:59
字号
Github论文
HuggingFace
Lab4AI
DeepSeek-OCR的核心创新在于利用视觉模态作为文本信息的高效压缩媒介。研究表明,一张包含文档文本的图像可以用比等效文本少得多的Token来表示丰富信息,这意味着通过视觉Token进行光学压缩可以实现极高的压缩率。
其核心表现可概括为两组关键数据:
这种突破的价值不仅在于OCR本身:对于受限于“长上下文处理能力”的大模型而言,DeepSeek-OCR提供了一种新解法——将超长文本转化为视觉图像后压缩输入,可大幅减少LLM的token消耗,为处理百万字级文档、历史上下文记忆等场景打开了通道。
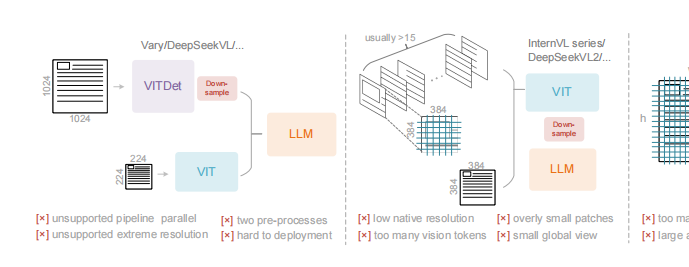
DeepEncoder:编码器+MoE解码器
为实现“高压缩比、低资源消耗”的目标,DeepSeek-OCR采用了“DeepEncoder(编码器)+DeepSeek3B-MoE(解码器)”的端到端架构,两者各司其职又高度协同。
1. DeepEncoder
作为模型的“压缩核心”,DeepEncoder需同时满足“高分辨率处理、低激活开销、少token输出”三大需求,其架构设计暗藏巧思:
2. DeepSeek3B-MoE
解码器采用混合专家(MoE)架构,在“性能与效率”间找到了平衡点:
性能表现
实验数据令人印象深刻:当文本Token数量在视觉Token的10倍以内(压缩率
责任编辑:CQITer新闻报料:400-888-8888 本站原创,未经授权不得转载
继续阅读




;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}