仅0.07B参数竟媲美72B大模型?百度这款OCR神器凭什么引爆GitHub
作者:佚名 时间:2025-11-15 16:07
前几天,百度在 Hugging Face 上发表了一篇博客,介绍了一款最新的轻量级文字识别模型 PP-OCRv5。这篇博客已连续一周登顶 Hugging Face 博客热度榜首(写稿时在榜单第二)。
博客地址:huggingface.co/blog/baidu/…
根据博客介绍,该模型仅0.07B参数,以千分之一参数量实现与72B参数大模型相媲美的OCR精度。
该模型属于百度开源OCR项目 PaddleOCR 套件中的一部分。截至目前,该项目 Star 数已突破 55k,累计下载量超过 900 万,在 GitHub 上的项目引用量高达 5.9k ,也是 GitHub Star 最高的中国 OCR 项目,流行程度极高。
而作为一名开发者,我比较关心的是:**它的实际表现如何?它能在生产环境中解决什么痛点?**OCR 在很多场景下都是刚需,但传统大模型 OCR 往往部署成本高、硬件要求高。这个号称“0.07B 参数就能媲美 72B 大模型”的模型,显然值得我花时间去试试。
模型介绍
从博客内容中看起来,PP-OCRv5 的核心卖点在于两个方面:轻量、准确。
从工程角度看,它的最大价值是:低资源环境依然能跑得动。不需要顶配 GPU,CPU 环境下也能保持不错的推理速度。这一点,对于移动端和大规模生产部署来说极具吸引力。
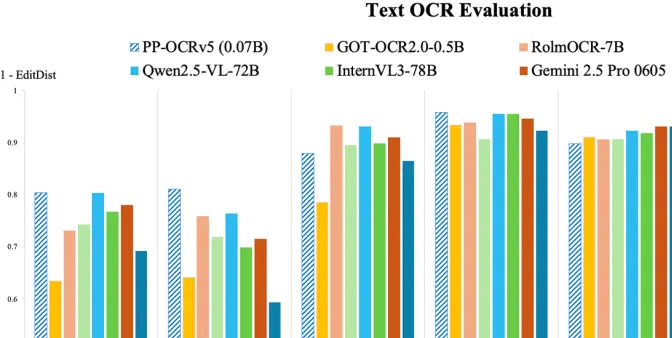
(图片来源于百度发布在huggingface上的博客)
实测体验
根据官方介绍,支持简体中文、繁体中文、中文拼音、英文、日文五种文字类型,以及手写、竖版、拼音、生僻字等复杂文本场景的识别。
我就试试中文和英文好了,直接用官方提供的体验环境,拿一些不同的图片来进行测试。
在线体验地址:aistudio.baidu.com/community/a…
网页标准字体
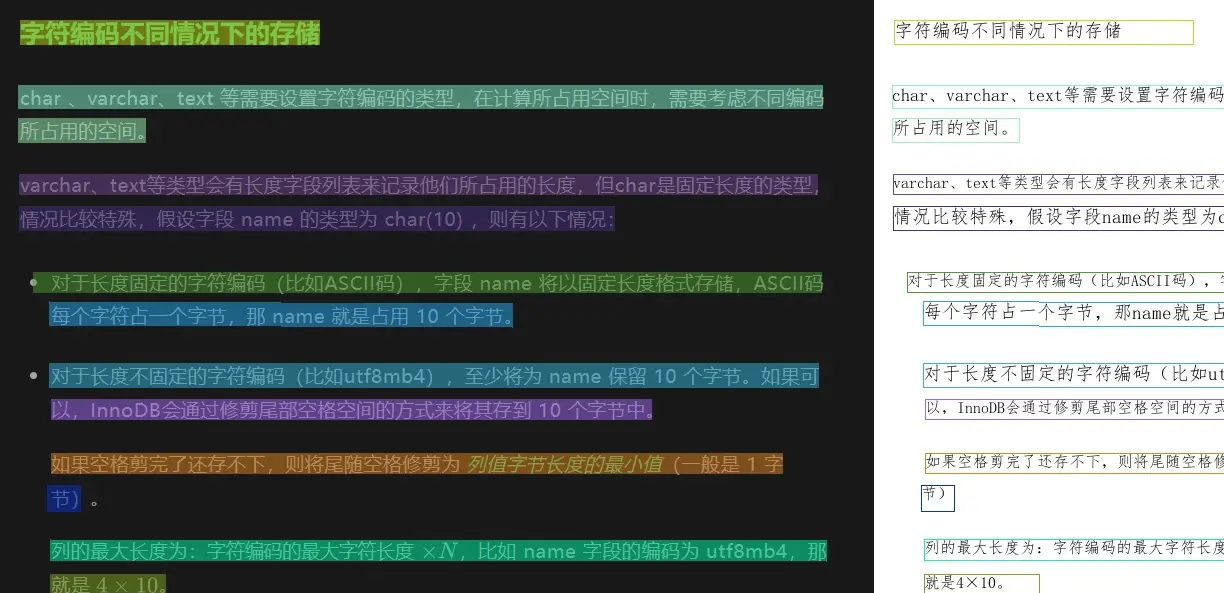
中文识别算是 PP-OCRv5 的强项,我拿了一段博客内容截图进行识别,包含少量英文,几乎无可挑剔,中文英文识别准确率都非常高。
这是一篇英文博客,也是比较标准的网页字体,识别无压力,准确度仍然很高。

我还测试了一些其他的标准字体截图,准确率都很高,就不一一展示了,没啥难度。
手写字体
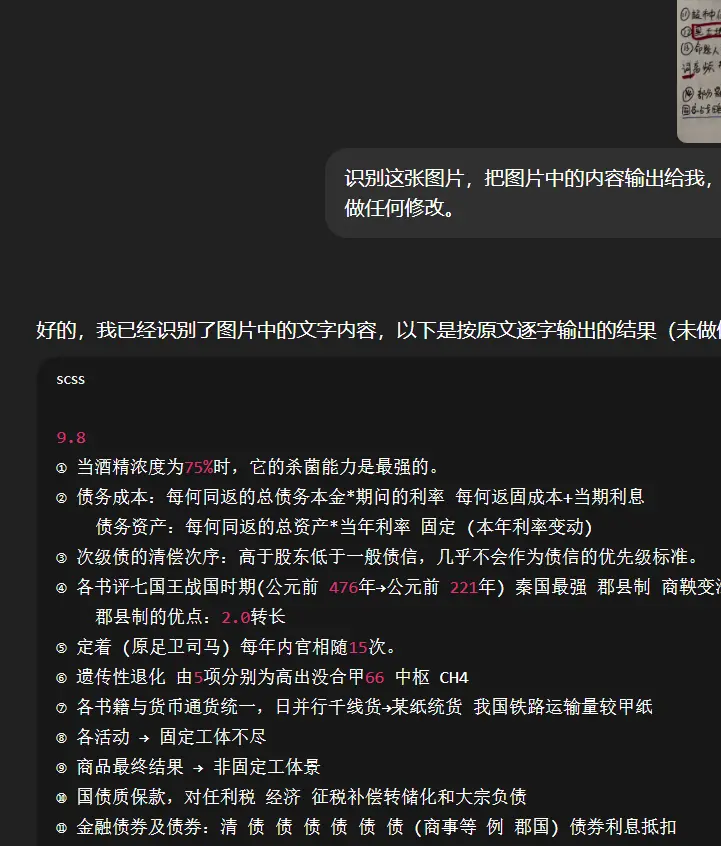
OK,上点难度朋友们。我直接问我对象要了一份手写的考公笔记来测试,大家可以放大来看看效果。


没想到,这么潦草的手写体,看了一眼,识别率竟然也超过90%。说实话,有几个字,我如果不仔细去看,也同样无法认出,果真是有实力的。
第二张图片,我也丢给GPT识别了下(模型GPT-5),准确率低很多,且貌似有幻觉产生,出现了一些不知道哪里来的字。确实差点意思,果然是没有专业的 OCR 模型准确率高。
体验感受
整体体验下来,优势很明显:
总结
作为一名开发者,我的结论是,PP-OCRv5 在许多生产场景都已经适用,例如票据识别、文档扫描、表格 OCR、移动端 OCR、政企应用等。甚至在一些不那么复杂的手写字体场景也同样适用,例如较为工整的手写笔记、课堂板书,或者比较规整的手写表格,都能识别得比较稳定。
PP-OCRv5 给我的最大感受是:小模型并不是只能做“玩具”,它在实际工程里完全能对标大模型。这或许代表了一种趋势:在特定垂直任务里,小模型经过精心设计和训练,可以颠覆大模型的垄断。
期待 PP-OCR 在未来继续进步,也推荐每个对 OCR 有需求的人都去试试 PP-OCRv5,不管你是科研党、工作党、还是独立开发者,它都可能给你带来惊喜。
开源地址:github.com/PaddlePaddl…
在线体验地址:aistudio.baidu.com/community/a…



;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}