从几台服务器到百亿资金系统!后端架构师8年血泪经验为何都聚焦在这关键一点?
作者:佚名 时间:2025-11-12 09:20

作为一名长期留意数据存储技术领域的从业人士,长久以来都在关注着这些方面情况,我察觉到就MySQL性能优化这件事情而言,一直以来始终都是开发者们热烈讨论的关键焦点。现处当今数据量急剧增长的环境态势之下,思索如何能够让这个堪称经典范畴的数据库系统以持久保持高效稳定的状态持续运行,这切实是一件值得投入深度精力去详细探讨的重要事情。
服务器配置基准
于具备16GB内存以及8核CPU的硬件环境当中,当MySQL数据库处于读写比例为8:1之情形时,其达成3000 QPS并且CPU占用保持在70%以内,此可被视作性能达标的参看标准。这般配置能够满足多数中小企业的实时业务需要,尤其是在用户量处于百万级之下的场景里展现出稳定的表现 。
通过Linux系统当中的top命令能够实时监测MySQL进程的CPU消耗情况,若察觉到持续超过70%阈值,那么就需要启动优化程序。对于企业运维团队而言应当建立常态化的监控机制,把业务高峰时段列为参考前提进行负载压力测试,进而能提前识别潜在的性能瓶颈点 。
关键参数调优
把innodb_buffer_pool_size参数设置成为物理内存的百分之七十五,能够明显地提升热点数据的缓存命中率,这项配置直接对数据读取效率产生影响,过小的缓存池会致使频繁的磁盘访问出现,让查询响应时间成倍地增大。
把innodb_log_file_size参数予以调整,能够对磁盘写入压力起到有效的缓解作用。当redo日志的写入位置快要接近检查点时,系统会进行强制刷盘的操作。将日志文件尺寸适当地扩大,可把这种操作之间的间隔从数分钟延长为数小时,以此降低I/O负载。
查询优化策略
开发者建立有效的索引体系,是数据库优化器倾向于选择扫描行数较少的执行方案所要求的。通过EXPLAIN语句分析查询计划的办法,能识别全表扫描操作,然后进行针对性改进 。
减少回表的次数能够直接地推动查询性能的提升,覆盖索引技术致使查询所需要的数据全然被涵盖于索引里面,从而避免了去访问主键索引的额外的开销,实际测试表明该技术能够让复杂查询的速度提高三至五倍。
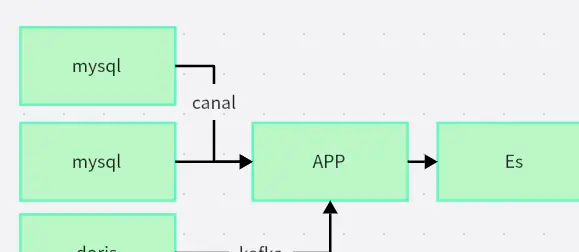
缓存与过滤机制
布隆过滤器能够有效地拦截针对那些不存在的数据发起的查询请求,这种属于概率型的数据结构,仅仅凭借使用少量的内存,便可以识别出那些绝对不在数据集中的键值,进而把无效请求阻挡在数据库层的前面,使其无法抵达。
尽管缓存数据同数据库之间存在着短暂的不一致情况,这种状况一般而言是能够被许可的,然而建立数据过期机制这件事却是必不可少的事宜。推荐运用LRU算法,使其能够自动将陈旧的数据予以淘汰,与此同时还要设定一最大存活的时长规模,籍此来避免冷数据长时间地对内存空间进行占据留用。
主从架构实践
借助二进制日志传输,MySQL原生主从同步机制达成数据冗余。仅通过在配置文件里设置server-id参数,并且建立复制账户,就能打造一主多从的分布式架构,读性能会随从节点数量增加而呈线性提升。
诸如Sharding-JDBC这般的中间件达成了读写分离的自动化路由,应用程序不必去修改业务代码,仅仅借助配置就能把写操作定向转移至主库,将读操作分发分派至从库,显著地降低了代码的侵入性。
数据一致性保障
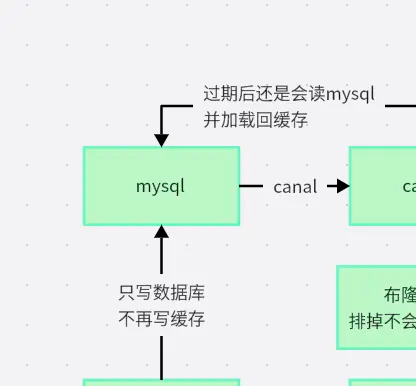
Canal组件借助解析MySQL二进制日志达成实时数据流捕获,其断点续传机制保证在网络异常等状况下数据不会丢失,只会产生秒级延迟,为异构系统同步给予可靠方案。
把离线对账任务当作最终一致性的保障措施,按照固定的周期去比对源库跟目标库之间的数据存在的差异,建议在业务处于低峰期进行全量校验,针对那些不一致的记录生成修复脚本,以此来保证跨系统数据的完整并且统一 。
站在各位技术同行的角度,在各位针对MySQL进行优化的实践进程当中,究竟什么样儿的技术方案能够以最为有效地方式,去解决掉性能瓶颈这一问题呢?欢迎来到评论区域把真实发生的案例分享出来,通过点赞这种行为来交流具备有价值的技术方面的经验嗯 。



;){kind=link}
和缓存(需注意雪崩问题)提升性能。读写分离是有效手段,通过主从同步和');){kind=link}
;){kind=link}
和缓存(需注意雪崩问题)提升性能。读写分离是有效手段,通过主从同步和');){kind=link}