腾讯QQ大数据:神盾推荐系统的超大规模参数学习探究
作者:媒体转发 时间:2018-09-13 09:07
本文介绍我们在推荐系统领域的大规模参数学习研究. 问题的起源是探究给每一个用户学习一个 ID 层级的表征, 而在千万量级的业务上, 学习如此特征将会牵涉到超十亿规模的参数学习. 对此我们根据推荐算法的特点, 实现了一个无需使用参数服务器, 在普通 Spark 能够运行的支持大规模参数学习的 FM 算法, 我们称之为 Elastic Factorization Machines (EFM). 从理论上, EFM 算法能够支持千亿规模的参数训练. 在实践中, 限于资源我们实现了一个十亿级的 EFM 算法, 并在线上对比 FM 取得 PV 点击率 5.0% 的提升.
效果说明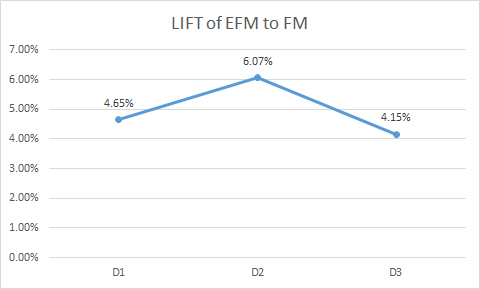
[ QQ 动漫某场景的三天 PV 点击率对比 ]
用户 ID 层级的表征学习推荐系统中, 用户的表征是一个非常重要的课题, 表征的粒度通常影响推荐算法的个性化程度. 当我们只能用性别的男/女来表征用户的时候, 算法能够给出的只是分群热度推荐. 而当我们能够刻画用户在每一个物品分类的兴趣的时候, 算法的便能够给不同的兴趣群体给出不一样的推荐. 越精细的用户表征, 推荐系统的个性化程度越高.
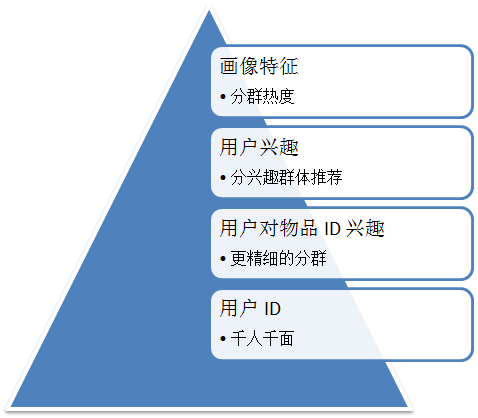
[ 越精细的用户表征, 推荐系统就越个性化 ]
而最精细的用户表征, 是用户 ID. 对每一个用户学习用户兴趣, 能够做到真正的千人千面. 但在实现上, 学习用户 ID 层级的表征通常会遇到计算量的问题, 这里主要的原因是用户 ID 层级特征量级与用户量直接相关, 以千万级用户的业务为例, 如果使用 FM 算法学习用户 ID 特征, 对每一个用户学习维度为 100 维的隐向量, 则整体参数量将会增加到 10亿级. 而如果这个业务的物品更新不快, 物品数能控制在数万规模, 则即便是用 “用户对物品兴趣” 这个用户表征也只需要训练百万级别的参数.
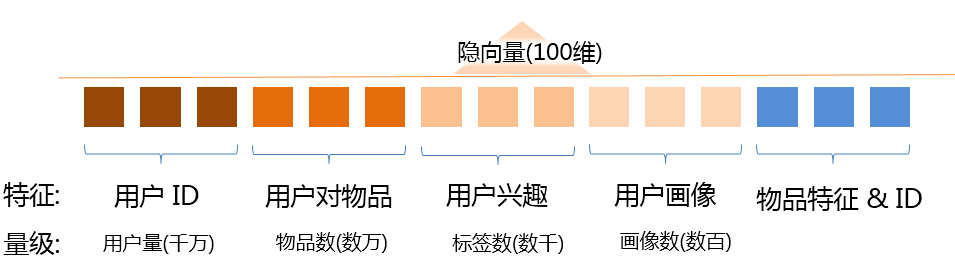
[ 各级别用户表征的特征量级对比 ]
无参数服务器实现大规模参数学习业界在大规模参数学习的解决方案是使用参数服务器. 背后的核心是分布式训练. 而市面上各个参数服务器在并行策略上也有不一样的划分, 包括下面两种情况:
• 数据并行
o 这种方法是把模型分发到每一个节点做训练, 但如果模型参数量本来就非常大, 将无法支持.
• 数据并行 + 模型按需并行
o 这种方法的初衷是考虑到并不是每一个训练数据块都需要所有的参数, 因此可以统计当前训练数据所需的参数, 并只向参数服务器请求这些参数. 但因为训练数据是随机分布的, 因而可能一个参数会被多个数据块请求, 这会导致较大的网络开销.
而当我们需要给每一个用户 ID 训练表征的时候, 同一个用户 ID 的参数, 应当仅被这个用户创造的样本所需要, 这个参数对应的梯度也只能从这些样本产生. 这意味着我们只需要让训练数据和模型同时做划分(分桶), 就能够让每个用户 ID 参数仅被一个数据块请求. 在这个思想下, 用户 ID 层级的参数可以分布式存储, 从而也不需要一个单点的参数服务器, 可以在普通的 Spark 上实现.

[ 不同类型的大规模参数训练方案对比 ]
整体的实现步骤如下, 用户 ID 层级的参数和训练数据都按照用户 ID 哈希分桶, 每一个参数块都被分发到对应的数据块上做训练. 与此同时其他特征也会被分发到每一个训练数据块上. 因为除开用户 ID 层级参数外, 其他参数(例如 Item ID)量级能够控制在百万以内, 从而可以分发到各个子结点的内存中. 从参数和训练数据中我们可以算得每一个参数的梯度, 而用户 ID 层级参数的梯度也只由这个训练数据块中产生, 从而可以做一个一一对应的分发把梯度推送到对应的参数块. 而其他参数因为量级较小, 可以做一个递归合并然后在内存更新.
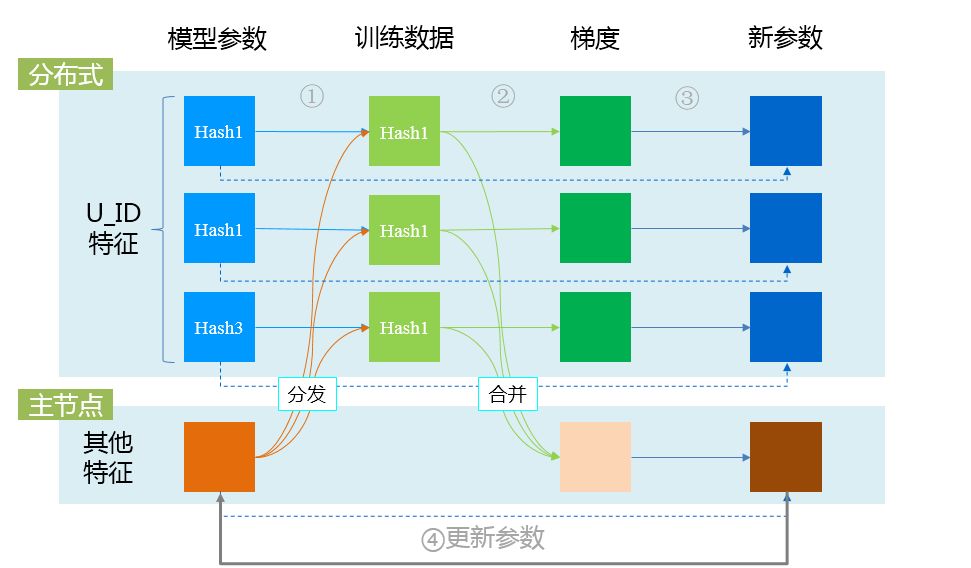
[ 无参数服务器实现大规模参数训练方案 ]
实现细节规模上限
这个实现从理论上能够支持任意量级的用户 ID 层级训练. 但受限于业务资源, 我们最高只测试过十亿级别的模型训练.
算法选择
按理只要是梯度下降法的优化算法都能够利用类似的方法去实现. 这里我们实现了 SGD 和 ADAM 两种方法, 发现 ADAM 算法作为一个自适应学习率的方法, 效果更好. 这两个算法的具体原理, 可以参见文献1.
Spark 大规模参数学习的工程实现




;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}