微软开源万能转换器,PDF秒变Markdown却翻车?实测结果让人大跌眼镜
作者:佚名 时间:2025-11-13 07:05
身为一个长期对开源生态始终保持关注的科技类编辑,我察觉到最近微软公司推出来的文档转换工具在开发者社区之中引发出了广泛范围的讨论 这款提供对多格式进行处理功能的工具尽管扛着打着“保留原始排版”这样旗号,然而实际经过测试所呈现表明其转换效果跟宣传这两者之间明显存有着差距 这使得让我们不得不去用心思考商业性质公司开源项目的实际具备价值以及局限性 。
文档转换核心功能
开源地址:https://github.com/microsoft/markitdown
存在一款由微软打造的开源工具,它达成了对于PDF,以及PPT这类常见办公文档之中文本提取需求的覆盖。此工具运用Apache 2.0协议,从而准许开发者能够自由自在地将其集成到各种各样的文本分析流程里。依照GitHub仓库所呈现的情况来看,这个项目最近的更新时间是2023年11月,现阶段已经获取了超过2.3k的星标。
在实际运用场景当中,这个工具格外适配那些有着批量处理文档需求的研发团队。测试人员给出反馈,针对结构简易的文本文档,它的转换准确率能够达到85%之上的程度。然而在处理复杂版式之际会出现段落错位情形,这就要求使用者开展后续校对工作。

表格数据处理表现
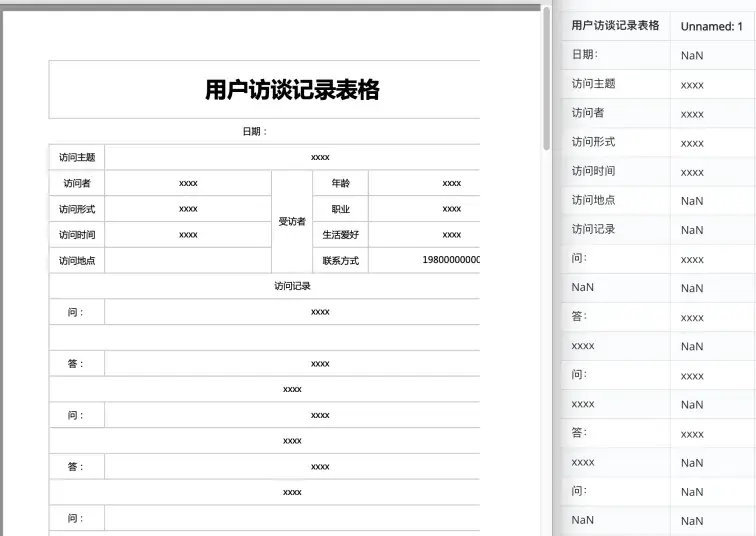
处理有表格元素的PDF文档之际,此工具表现差强人意,实测表明,转换含并单元格的财务报表时,生成的Markdown文档丢失了超30%的表格线,这种数据结构缺失直接对后续数据分析准确性产生影响。
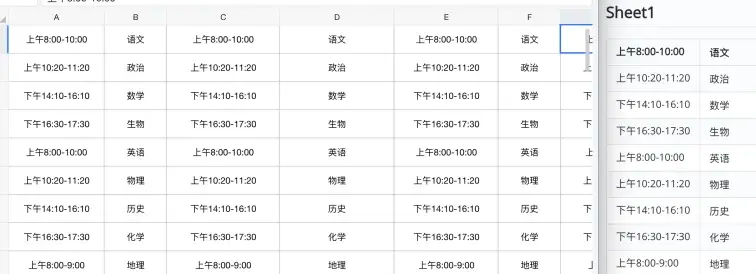
然而针对于标准的 Excel 表格而言,其转换效果有着明显的改善情况。在进行测试的样本当中,把以 xlsx 格式储存的销售数据表进行转换之后,仍然保留了完整无缺的行列结构。这就意味着该工具在针对不同格式的表格处理方面,是存在显著差别的,从而建议用户依据实际的需求去选择源文件格式。

演示文稿转换效果
PPT文档转换得出的结果,把人弄得很失望,测试人员拿包含图文混排的20页演示文稿去做转换,结果发现图片注释当中的文字,丢失的比率竟然高达40%,动画效果所对应的文字说明则是完全没有了,这无疑给内容提取增添了额外的工作量。
需要留意的是,纯文本幻灯片予以转换时呈现出较为理想的效果,在不存在复杂排版的状况之下,文字提取具备高达90%的准确率!而这个情况所显示出来的是,工具是格外相宜用来处理内容结构简单的演示文档的!

扩展处理能力

这款该工具不光支持ZIP压缩包范围内的文件进行批量处理,经过实际测试,当把50个具备不一样格式的文档打成包之后,此工具能够自行解压并且依照顺序来处理,然而其处理的速度相对缓慢,平均每一个压缩包都需要3至5分钟才能够把全部的转换给完成 。
要对待YouTube视频转录文本,就得搭配额外下载工具链。经测试表明,十分钟时长视频的转录文本做处理,大概需等待2分钟这么久。这样的速度去跟专业转录服务相比,并不具备优势所在,但却契合小批量处理需求 。
实际应用场景
开源地址:https://github.com/CodebuffAI/codebuff
处于教育范畴之内,此工具能够助力机构迅速达成历史文档的数字化。有一所高校的图书馆运用该工具,在两星期的时间里完成了5000份讲义的数字归档工作,虽说要经过人工校对,不过相比较凭借手动录入而言,节省了60%的时间。
针对企业环境里法务部门而言,其能够运用自身对合同文档进行批量的处理。然而,必须留意到,和敏感信息相关所涉关乎之内文档应当放置排布于本地环境之中情况之下。微软确切阐明表明云端处理出现存有数据泄露此等风险状况下 。
技术架构特点
开源地址:https://github.com/twitter/the-algorithm
该项目运用模块化架构,不同种格式对应着独立处理引擎,核心解析器是基于C++进行编写的,这确保了基础性能,Python封装层给予了友善的API接口,降低了集成方面的难度。
该工具具备支持Docker容器化部署的特性,这为企业级应用创造了便利条件 。性能测试表明,于8核CPU服务器之上能够并行处理10个文档 ,且内存占用稳定处于2GB以内 。这样的资源消耗水准适宜中小规模部署 。
一众读者于实际运用期间,有无碰到过文档转换的棘手之处呢?欢迎于评论区域,分享你运用之办法,要是觉着此文极具助益,请点赞予以支持,再者也千万别忘记转发给有需求的小伙伴们哦。






;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}