鲜为人知的混沌工程,到底哪里好?
作者:CQITer小编 时间:2019-02-01 21:29

一、为什么需要混沌工程?
(翻译自Chaos Engineering电子书)
1.1 混沌工程与故障测试的区别
混沌工程是在分布式系统上进行实验的学科, 目的是建立对系统抵御生产环境中失控条件的能力以及信心,最早由Netflix及相关团队提出。
故障演练是阿里巴巴在混沌工程领域的产品,目标是沉淀通用的故障模式,以可控成本在线上重放,以持续性的演练和回归方式运营来暴露问题,不断推动系统、工具、流程、人员能力的不断前进。
混沌工程、故障注入和故障测试在关注点和工具中都有很大的重叠。
混沌工程和其他方法之间的主要区别在于,混沌工程是一种生成新信息的实践,而故障注入是测试一种情况的一种特定方法。当想要探索复杂系统可能出现的不良行为时,注入通信延迟和错误等失败是一种很好的方法。但是我们也想探索诸如流量激增,激烈竞争,拜占庭式失败,以及消息的计划外或不常见的组合。如果一个面向消费者的网站突然因为流量激增而导致更多收入,我们很难称之为错误或失败,但我们仍然对探索系统的影响非常感兴趣。同样,故障测试以某种预想的方式破坏系统,但没有探索更多可能发生的奇怪场景,那么不可预测的事情就可能发生。
测试和实验之间可以有一个重要的区别。在测试中,进行断言:给定特定条件,系统将发出特定输出。测试通常是二进制态的,并确定属性是真还是假。严格地说,这不会产生关于系统的新知识,它只是将效价分配给它的已知属性。实验产生新知识,并经常提出新的探索途径。我们认为混沌工程是一种实验形式,可以产生关于系统的新知识。它不仅仅是一种测试已知属性的方法,可以通过集成测试更轻松地进行验证。
混沌实验的输入示例:
模拟整个区域或数据中心的故障。
部分删除各种实例上的Kafka主题。
重新创建生产中发生的问题。
针对特定百分比的交易服务之间注入一段预期的访问延迟。
基于函数的混乱(运行时注入):随机导致抛出异常的函数。
代码插入:向目标程序添加指令和允许在某些指令之前进行故障注入。
时间旅行:强制系统时钟彼此不同步。
在模拟I/O错误的驱动程序代码中执行例程。
在 Elasticsearch 集群上最大化CPU核心。
混沌工程实验的机会是无限的,可能会根据分布式系统的架构和组织的核心业务价值而有所不同。
1.2 实施混沌工程的先决条件
要确定是否已准备好开始采用混沌工程,需要回答一个问题:你的系统是否能够适应现实世界中的事件,例如服务故障和网络延迟峰值?
如果答案是“否”,那么你还有一些工作要做。
混沌工程非常适合揭露生产系统中未知的弱点,但如果确定混沌工程实验会导致系统出现严重问题,那么运行该实验就没有任何意义。先解决这个弱点,然后回到混沌工程,它将发现你不了解的其他弱点,或者它会让你发现你的系统实际上是有弹性的。混沌工程的另一个基本要素是可用于确定系统当前状态的监控系统。
1.3 混沌工程原则
为了具体地解决分布式系统在规模上的不确定性,可以把混沌工程看作是为了揭示系统弱点而进行的实验。破坏稳态的难度越大,我们对系统行为的信心就越强。如果发现了一个弱点,那么我们就有了一个改进目标。避免在系统规模化之后问题被放大。以下原则描述了应用混沌工程的理想方式,这些原则来实施实验过程。对这些原则的匹配程度能够增强我们在大规模分布式系统的信心。
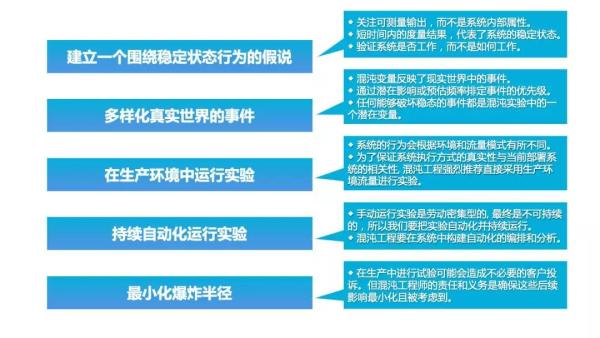
二、阿里巴巴在混沌工程领域的实践:故障演练
混沌工程属于一门新兴的技术学科,行业认知和实践积累比较少,大多数IT团队对它的理解还没有上升到一个领域概念。阿里电商域在2010年左右开始尝试故障注入测试的工作,开始的目标是想解决微服务架构带来的强弱依赖问题。后来经过多个阶段的改进,最终演进到 MonkeyKing(线上故障演练平台)。从发展轨迹来看,阿里的技术演进和Netflix的技术演进基本是同时间线的,每个阶段方案的诞生都有其独特的时代背景和业务难点,也可以看到当时技术的局限性和突破。
2.1 建立一个围绕稳定状态行为的假说





;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}