深度 | 线下场景的客流数字化探索与应用
作者:媒体转发 时间:2019-01-08 21:48

在互联网时代,数据是所有应用的基础,淘宝的商家可以基于商品历史的点击成交量来判断店内各个商品的情况,并做出相应的运营行为,淘宝的买家会根据商品历史的成交数据,评论数据等,来辅助自己判断是否进行购买,同时我们平台也会基于用户和商品的历史数据,来训练模型,预测各个商品的点击率,预测各个用户的偏好,使展示的结果更符合用户的需求。可以看出,数据对于各个不同的角色都有很重要的作用。
在互联网中,获取数据相对容易,反观线下零售场景,大部分数据都是缺失的,商家并不知道店内多少商品被浏览了,多少商品被试穿了,买家也不知道各件商品的历史数据。
因此,我们的客流数字化相关的探索,就是要将线下的用户和商品的行为数据收集起来,让线下的行为也能有迹可循,为商业决策和市场运营提供准确有效的数据支撑,将传统零售中的导购经验逐渐数字化成可量化和统计的数字指标,能够辅助商家运营,同时帮助用户进行决策。基于这些数据,也能够让算法在线下发挥更大的作用。
整体方案
整体方案如下图所示,方案涉及场外的选品策略指导,线下引流,进店的人群画像,顾客轨迹跟踪,人货交互数据沉淀,试衣镜互动/推荐,以及离店后的线上二次触达。从场外到场内再到线上,构成了整体全流程的产品方案。
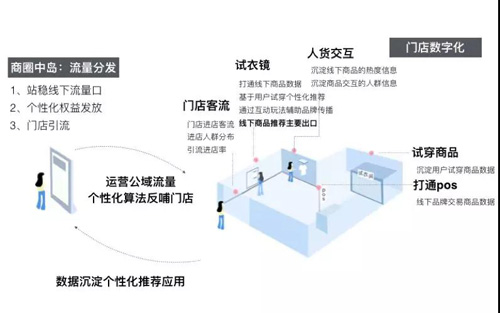
客流数字化探索
在门店客流数字化的探索中,硬件部署上,我们使用了门店已有的监控摄像头和RFID标签,并结合视觉及射频相关技术,通过在门店部署GPU终端进行计算。技术方案上,我们基于人脸识别技术,识别进店用户的性别,年龄,新老客等基础属性,并通过行人检测跟踪与跨摄像头的行人重识别技术跟踪用户在门店内的动线变化,同时得到整体门店各个区域的热力图分布,此外,还通过摄像头与RFID 多传感器融合的技术识别用户在门店内的行为,包括翻动,试穿等,精确定位门店内各个商品的浏览与试穿频次以及用户在线下的偏好。下面会主要介绍其中的行人检测,行人重识别和动作识别这3个技术方向相关的优化。
行人检测
在新零售的客流数字化场景中,我们需要通过监控摄像头对门店客流的进店频次、性别、动作、行为轨迹、停留时间等全面的记录和分析。要达到我们的目标,首先需要能够检测并识别出摄像头中的行人。
虽然目前YOLO等目标检测算法可以做到近乎实时的计算性能,但其评估环境都是Titan X、M40等高性能GPU,且只能支持单路输入。无论从硬件成本或是计算能力方面考虑,这些算法都无法直接应用到真实场景中。当然YOLO官方也提供了像YOLOv3-Tiny这种轻量级的模型方案,但模型性能衰减过大,在COCO上mAP下降超过40%。同时现有目标检测方案的泛化能力还比较弱,不同场景的差异对模型性能会造成较大的影响。门店场景下的视角、光线、遮挡、相似物体干扰等情况与开源数据集差异较大,直接使用基于VOC、COCO数据集训练的模型对该场景进行检查,效果非常不理想。我们分别针对模型的性能和在实际数据集的效果两方面做了相应的优化。
网络结构精简与优化
我们在YOLO框架的基础上对模型进行改进,实现了一种轻量级实时目标检测算法,在服饰门店的真实场景下,和YOLOv3相比,模型性能下降不超过2%,模型大小缩小至原来的1/10,在Tesla P4上对比FPS提升268%,可直接部署到手机、芯片等边缘设备上,真实业务场景中一台GTX1070可以同时支持16路摄像机同时检测,有效节约了门店改造的经济成本。
标准YOLOv3的网络结构有106层,模型大小有237M,为了设计一个轻量级的目标检测系统,我们使用Tiny DarkNet来作为骨干网络,Tiny DarkNet是一个极简的网络结构,最大通道数为512,模型大小仅4M,该模型结构比YOLO官方的YOLOv3-Tiny的骨干网络还要精简,但精简网络会造成特征抽取能力的衰减,模型性能下降剧烈,在我们人工标注的2万多张服饰门店场景数据集上,替换后的Tiny DarkNet + FPN结构较原生结构的AP-50(IOU=0.5)下降30%。我们在特征抽取网络之后进行Spatial Pyramid Pooling[10],与原特征一起聚合,之后通过下采样与反卷积操作将不同层级特征合并,希望将底层的像素特征和高层的语义特征进行更充分的融合来弥补特征抽取能力的下降,整体网络结构如下图所示,精简后的检测模型大小约为原来的1/10。
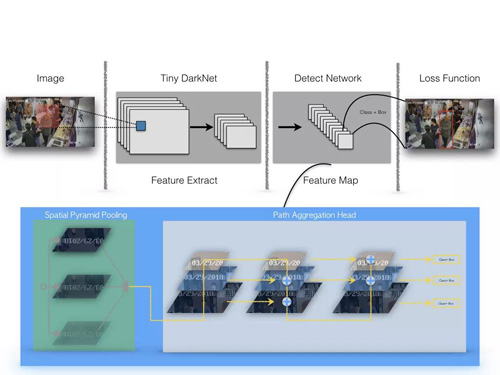
目标检测网络结构
知识蒸馏进一步优化




;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}