阿里Blink SQL关键技术及实现原理
作者:媒体转发 时间:2019-01-04 09:45
介绍Blink SQL的几个关键技术,以及实现原理,并通过两个实例来阐述具体的功能效果。
六个特点和背景介绍

(Blink架构)
Blink作为一个纯流式的计算平台,具备秒级甚至毫秒级的延时,能够快速容错,比如在某个计算节点挂掉的时候可以快速恢复。它还支持动态扩容,针对流计算场景做了大量优化,具备高吞吐和高资源利用率的极致性能,同时解决了非常明显的数据乱序的问题,并且支持大数据量的流计算请求。
什么是BlinkSQL
BlinkSQL是在FlinkSQL基础上新增了大量的丰富功能和性能优化。SQL作为声明式的可优化的语言具备很大的优势,Blink的SQL查询优化器会对用户SQL进行优化,制定最优的执行计划以获取高性能。同时SQL易于理解,用它编写的业务逻辑清晰明了。
虽然SQL被更多的用于批处理,但是在流计算场景下同样也适用。从处理的数据集合来看,流处理的数据是无穷的,而批处理面对的是有限集合。从内部处理逻辑来看,批处理是单次作业,流处理的运作持续不断,并且会对历史数据进行修正。

上图展示的是一个携带时间戳和用户名的点击事件流,我们先对这些事件流进行流式统计,同时在最后的流事件上触发批计算。流计算中每接收一个数据都会触发一个结果,可以看到最后的事件无论是在流还是批上计算结果都是6。这说明只要SQL语句和数据源相同,流和批的计算结果就不会存在差异。相同的SQL在流和批这两种模式下,语义相同,最终结果就会一致。
五个概念和一个实现
1. 流表对偶性
流表对偶性是指流表转换信息无损,具有对偶性。
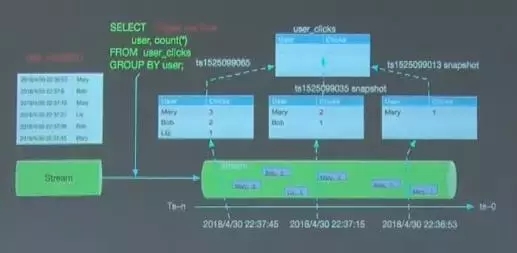
传统数据库表有两个最明显的特征schema和data,流同样也有schema和data,另外还有一个重要属性time,随着时间的推移数据会不断涌入流中。
上图中在对一个用户名关系表进行DML操作,每insert一条语句后会触发一个统计查询,按user维度分组做count统计。图中插入第一条数据后,输入的是(mary , 1),接着再插入数据就会输出(Bob , 2)、(mary , 1),在进行操作的时候虽然没有显示的涉及到时间,但是其实都隐含了一个操作时间,从本质上讲,传统数据库表中也有time属性。
这样的话单就属性来看数据库表和流式就是一样的,我们可以把一个具体的表可以看做是流上某一时间切片的数据。
2. 动态表

随着时间变化不断变化的表可以称之为动态表,这个概念不适用于传统数据库表。因为传统数据库有着事务控制,在执行查询的那一刻表的内容不会有变化,所以是静态表。而流上的数据即使在查询的时候也还是在变化,数据进行回放的时候,可以Replay成一张动态表,而动态表的changelog又形成了流。
3. 持续查询 & 增量计算
持续查询是流计算特有的,不断更新结果,执行运行的查询。它是保证低延迟和数据更新的基础。
增量计算是一种可以提高流计算性能的计算实现,流上的每一条数据都会利用上一条计算结果进行聚合和统计计算。
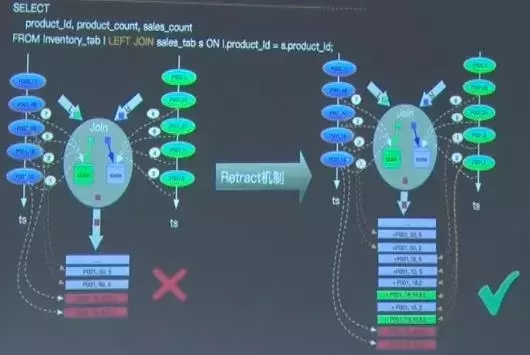
4. Early Emit & Retraction
Early Emit是为了保证流计算的低延时需求,将计算结果尽早的流到下游。由于流计算的结果会随着时间改变,因此即使上游的计算结果在发出的那一刻是正确的,但是随后又会产生新的结果,这样下游当初接收的数据就是陈旧的。Retraction解决的就是这一问题,为了保障流计算语义正确性,将Early Emit的计算结果撤回并发出正确的计算结果。
5. 双流JOIN实现
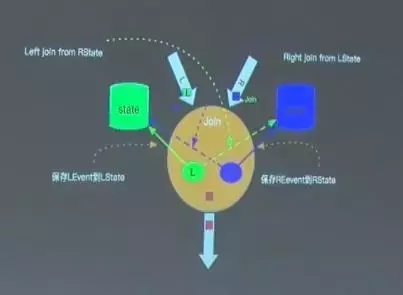
对于双流join,由于流上的流速不一定相同,有可能会出现查询的时候数据不存在,后续才出现数据的情况。上图是Blink的join方案,将左边的数据存储在一个state中,并且对右边的state做join查询。同理右边的数据处理也是一样,先存储在一个state中,然后join查询另一个state。





;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}