商品标题这么长长长长长,阿里工程师如何解决?
作者:媒体转发 时间:2018-12-05 21:52

商品标题是卖家和买家在电商平台沟通的重要媒介。在淘宝这样的电商app中,用户与推荐、搜索等系统的交互时所接受到的信息,主要由商品标题、图片、价格、销量以及店铺名等信息组成。这些信息直接影响着用户的点击决策。而其中,算法能够主动影响的集中在标题与图片上。本文所述工作,关注于商品标题生成,更具体地来讲,是商品的短标题的生成。
背景
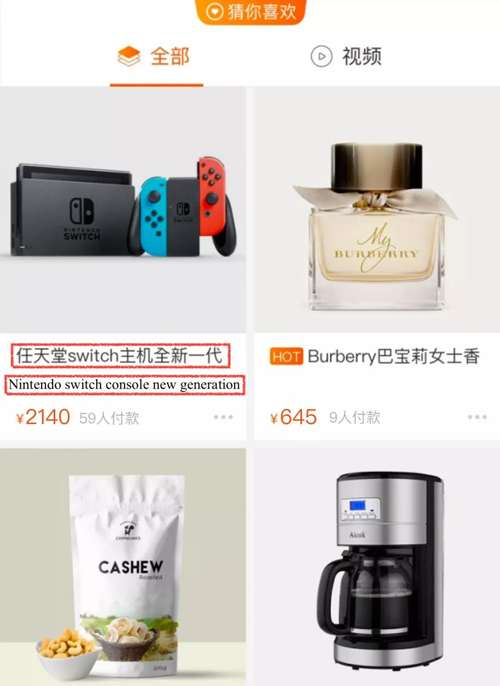

图1. 猜你喜欢推荐结果展示图以及商品详情页截图(目前猜你喜欢同时存在一行以及两行标题情况)。商品原始标题往往过长(平均长度30字左右),在结果页中无法完整显示,只能点击进入商品详情页才能看到商品完整标题。
当前淘系商品(C2C)标题主要由商家撰写,而商家为了SEO,往往会在标题中堆砌大量冗余词汇,甚至许多与商品并不直接相关的词汇,以提高被搜索召回的概率,以及吸引用户点击。这引起两方面的问题:
这些标题往往过长,以往pc时代这并不是一个严重问题。但现在已经全面进入移动互联网时代,手淘用户也几乎都是移动端用户,这些冗长的商品标题由于屏幕尺寸限制,往往显示不全,只能截断处理,严重影响用户体验。如图1所示,在推荐的展示页中,标题往往显示不全,影响体验。用户若想获取完整标题,还需进一步点击进入商品详情页。
另一方面,这些原始长标题是为了搜索做的SEO,对于推荐的match阶段,其实并无帮助。甚至,其中许多无关冗余词汇还会起到噪声作用,并且也会对用户的浏览决策起到干扰作用。
因此,使用尽可能短的文本体现商品的核心属性,引起用户的点击和浏览兴趣,提高转化率,是值得深入研究的问题。
问题形式化
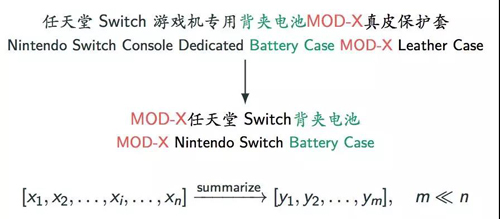
商品短标题的生成或者压缩,可以看作一种特殊的文本摘要任务。类似于Alexander Rush等人提出的sentence summarization任务[1,2]。但相比普通的sentence summarization任务,作为特定电商领域且跟用户消费密切相关的一个任务,商品短标题的生成具有一些更显式且严格的限制。此工作中,我们主要将其抽象为两点:
不能引入无关信息。商品的短标题尽量保留原始标题中的用词,避免引入其他信息。一方面这是因为原始标题中的词语往往都是卖家为了点击率等考虑精挑细选的,已经足够优秀;另一方面,引入其他信息虽然能够带来更多的变化,但也增加了犯错的可能。如为Nike的鞋子标题生成了Adidas关键字,这类事实性的错误在wiki style类的文本摘要中经常发生,已引起研究人员的重视[3],但在新闻之类的摘要中,人们往往还能忍受。对于电商平台来说,这类错误是不能容忍的。
需要保留商品的关键信息(如,品牌,品类词)。商品的短标题如果丢失了品牌或者品类词,一方面对用户来说非常费解,影响体验;另一方面也容易引起卖家的不满投诉。
这两个约束,在普通的句子摘要任务中,同样也成立,但他们并没有电商领域中如此严格。
针对这些问题,我们基于Pointer Netowrk [4],提出Multi-Source Pointer Network (MS-Pointer)来显式建模这两个约束,生成商品短标题。
首先,对于约束1,我们使用Pointer Network框架将商品短标题摘要建模成一个extractive summarization(抽取式摘要)问题(Pointer Network是一种特殊的Seq2Seq模型结构,具体下一小节介绍)。对于约束2,我们尝试在原有的标题encoder之外,引入关于商品背景知识信息的另一个encoder (knowledge encoder),这个encoder编码了关于商品的品牌以及品类词信息,其作用一方面在于告诉模型商品的品牌和品类词信息,另一方面在于pointer mechanism可以直接从这个encoder中提取商品的品牌等信息。
最终,MS-Pointer可以使用data-driven的方式学习从这多个encoder中提取相应的信息来生成商品的短标题,比如从knowledge encoder中选择品牌信息,而从title encoder中选择丰富的描述信息。
这里需要说明两个问题。
对于抽取式摘要,基于删除的方法(Deletion Based)一样可以使用。比如Filippova等人[5]便基于seq2seq提出了在decode端输出原始title每个词保留与否的label,这是一个特殊的seq2seq模型,与普通的seq2seq模型decoder输入是summarization不同,这个模型的decoder的输入还是原始标题,输出并不是生成词,而是输入词保留与否二分类的label。然而,为了让摘要结果更加通顺易读,摘要中经常存在word reordering现象[6],Deletion Based方法并不能很好地处理这问题。在我们收集的训练数据中,就发现有超过50%的数据有word reordering现象。





;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}