让天下没有难用的搜索:阿里搜索如何成长为贴心“暖男”?
作者:网友投稿 时间:2018-11-20 21:07

第十个双11已圆满结束,但是技术的探索永不止步。阿里技术推出《十年牧码记》系列,邀请参与历年双11大战的核心技术大牛,一起回顾阿里技术的变迁。
近十年,机器智能在越来越多的领域走进和改变着我们的生活。在互联网领域,机器智能则是得到了更普遍和广泛的应用。作为电商平台的基石,商品搜索团队一直在打造适合电商平台的机器智能体系。而每年双11,则是验证智能化进程的试金石。今天,阿里资深算法专家元涵带你穿越时空,感受双11场景下搜索智能化的十年演进道路。
阿里搜索技术体系演进至今天,基本形成了由offline、nearline、online三层体系,分工协作,保证电商平台上,既能适应日常平稳流量下稳定有效的个性化搜索及推荐,也能够去满足电商平台对促销活动的技术支持,实现在短时高并发流量下的平台收益最大化。
可以看到,十年双11的考验后,搜索智能化体系逐渐打造成型,已经成为电商平台稳定健康发展的核动力,主要分为四个阶段:自主研发的流式计算引擎Pora初露锋芒;双链路实时体系大放异彩;“深度学习+强化学习”初步探路;全面进入深度学习时代。下面我们就来一起看一下。
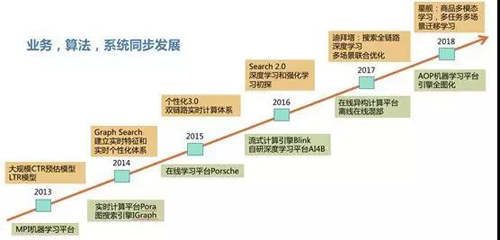
阶段一:初露锋芒——自主研发的流式计算引擎Pora
技术的演进是伴随解决实际业务问题和痛点发展和进化的。2014年双11,通过BI团队针对往年双11的数据分析,发现即将售罄的商品仍然获得了大量流量,剩余库存无法支撑短时间内的大用户量。主售款(热销sku)卖完的商品获得了流量,用户无法买到商品热销的sku,转化率低;与之相对,一些在双11当天才突然展露出来的热销商品却因为历史成交一般没有得到足够的流量。
针对以上问题,通过搜索技术团队自主研发的流式计算引擎Pora,收集预热期和双11当天全网用户的所有点击、加购、成交行为日志,按商品维度累计相关行为数量,并实时关联查询商品库存信息,提供给算法插件进行实时售罄率和实时转化率的计算分析,并将计算结果实时更新同步给搜索和推荐引擎,影响排序结果。第一次在双11大促场景下实现了大规模的实时计算。算法效果上,也第一次让大家感受到了实时计算的威力,PC端和移动端金额也得到显著提升。
阶段二:大放异彩——双链路实时体系
2014年双11,实时技术在大促场景上,实现了商品和用户的特征实时,表现不俗。
2015年搜索技术和算法团队继续推动在线计算的技术升级,基本确立了构筑基于实时计算体系的【在线学习+决策】搜索智能化的演进路线。
早先的搜索学习能力,是基于批处理的离线机器学习。在每次迭代计算过程中,需要把全部的训练数据加载到内存中计算。虽然有分布式大规模的机器学习平台,在某种程度上批处理方法对训练样本的数量还是有限制的。在线学习不需要缓存所有数据,以流式的处理方式可以处理任意数量的样本,做到数据的实时消费。
接下来,我们要明确两个问题:为什么需要在线学习呢?以及为什么实现秒级的模型更新?
在批量学习中,一般会假设样本独立服从一个未知的分布,但如果分布变化,模型效果会明显降低。而在实际业务中,很多情况下,一个模型生效后,样本的分布会发生大幅变化,因此学到的模型并不能很好地匹配线上数据。实时模型,能通过不断地拟合最近的线上数据,解决这一问题,因此效果会较离线模型有较大提升。那么为什么实现秒级分钟级的模型更新?在双11这种成交爆发力强、变化剧烈的场景,秒级实时模型相比小时级实时模型时效性的优势会更加明显。根据2015年双11实时成交额情况,前面1小时已经完成了大概总成交的1/3,小时模型就无法很好地捕获这段时间里面的变化。
基于此,搜索技术团队基于Pora开发了基于parameter server的在线学习框架,如下图所示,实现了在线训练,开发了基于pointwise的实时转化率预估模型,以及基于pairwise的在线矩阵分解模型。并通过swift输送模型到引擎,结合实时特征,实现了特征和模型双实时的预测能力。
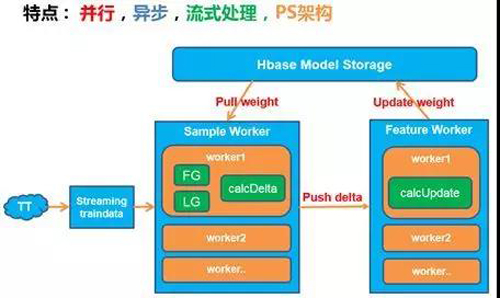
在线学习框架





;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}