AutoML、AutoKeras......这四个「Auto」的自动机器学习方法你分得清吗?
作者:网友投稿 时间:2018-11-12 16:31
让我们先来看一个简短的童话故事…
从前,有一个魔法师,他使用一种无人再使用的编程语言,在一种无人再使用的框架下训练模型。一天,一位老人找到他,让他为一个神秘的数据集训练一个模型。
这位魔法师孜孜不倦,尝试了数千种不同的方式训练这个模型,但很不幸,都没有成功。于是,他走进了他的魔法图书馆寻找解决办法。突然,他发现了一本关于一种神奇法术的书。这种法术可以把他送到一个隐藏的空间,在那里,他无所不知,他可以尝试每一种可能的模型,能完成每一种优化技术。他毫不犹豫地施展了这个法术,被送到了那个神秘的空间。自那以后,他明白了如何才能得到更好的模型,并采用了那种做法。在回来之前,他无法抗拒将所有这些力量带走的诱惑,所以他把这个空间的所有智慧都赐予了一块名为「Auto」的石头,这才踏上了返程的旅途。
从前,有个拥有「Auto」魔石的魔法师。传说,谁掌握了这块魔法石的力量,谁就能训练出任何想要的模型。

哈利波特与死亡圣器
这样的故事太可怕了,不是吗?我不知道这个故事是不是真的,但在现代,机器学习领域的头号玩家们似乎很有兴趣将这样的故事变成现实(可能会略有改动)。在这篇文章中,我将分享哪些设想是可以实现的,并帮助你直观地理解它们的设计理念(尽管所有工具的名字中都有「auto」这个词,但它们之间似乎并没有共同之处)。
动机——人生艰难
在给定的数据集中实现当前最佳模型性能通常要求使用者认真选择合适的数据预处理任务,挑选恰当的算法、模型和架构,并将其与合适的参数集匹配。这个端到端的过程通常被称为机器学习工作流(Machine Learning Pipeline)。没有经验法则会告诉我们该往哪个方向前进,随着越来越多的模型不断被开发出来,即使是选择正确的模型这样的工作也变得越来越困难。超参数调优通常需要遍历所有可能的值或对其进行抽样、尝试。然而,这样做也不能保证一定能找到有用的东西。在这种情况下,自动选择和优化机器学习工作流一直是机器学习研究社区的目标之一。这种任务通常被称为「元学习」,它指的是学习关于学习的知识。
AZURE 的自动化机器学习(试用版)
开源与否:否
是否基于云平台:是(可以完成任何计算目标的模型的评价和训练)
支持的模型类别:分类、回归
使用的技术:概率矩阵分解+贝叶斯优化
训练框架: sklearn
这种方法的理念是,如果两个数据集在一些工作流中能得到类似的(即相关的)结果,那么它们在其它的工作流中可能也会产生类似的结果。这听起来可能似曾相识。如果你以前处理过推荐系统的协同过滤问题,你就知道「如果两个用户过去喜欢相同的项目,那么将来他们喜欢相似项目的可能性就会更大」。
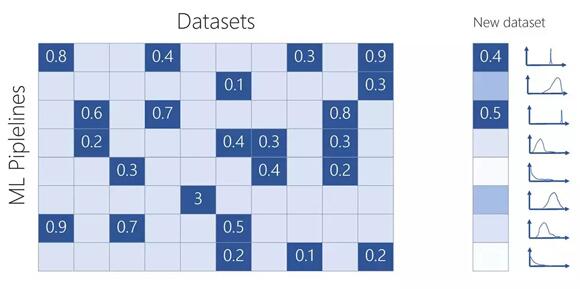
由工作流 P 和数据集 D 组成的输入矩阵的可视化。数字对应于数据集 D 在工作流 P 上得到的平衡均值。
要解决这个问题意味着两件事:学习一种隐藏的表示方法来捕获不同数据集和不同机器学习工作流之间的关系,以预测某工作流在给定数据集上能够获得的准确率;学习一种函数,能够成功地告诉你下一步应该尝试哪个工作流。第一个任务是通过创建一个平衡后的准确率组成的矩阵来完成的,不同的工作流可以应对不同的数据集。论文《Probabilistic Matrix Factorization for Automated Machine Learning》描述了该方法,详细说明了他们在超过 600 个数据集上尝试的 42,000 个不同的机器学习工作流。也许这与你今天在 Azure 的试用版中看到的是不同的,但它可以为你提供一种思路。作者指出,隐藏表征不仅成功地捕获了关于模型的信息,而且成功地捕获了关于超参数和数据集特征的信息(注意,这个学习过程是以无监督的方式进行的)。
目前所描述的模型可以作为已经评估的工作流的函数来预测每个机器学习工作流的预期性能,但是还没有对下一步应该尝试哪个工作流给出任何指导。由于他们使用的是矩阵分解的概率版本,该方法可以生成关于工作流性能的预测后验分布,从而允许我们使用采集函数(贝叶斯优化)来指导对机器学习工作流空间的探索。基本上,该方法可以选择出下一个可以最大化预期的准确率提升的工作流。





;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}