超参数搜索不够高效?这几大策略了解一下
作者:网友投稿 时间:2018-10-15 09:47
整天 babysitting 深度学习模型是不是很心累?这篇文章或许能帮到你。本文讨论了高效搜索深度学习模型最佳超参数集的动机和策略。作者在 FloydHub 上演示了如何完成这项工作以及研究的导向。读完这篇文章后,你的数据科学工具库将添加一些强大的新工具,帮助你为自己的深度学习模型自动找到最佳配置。
与机器学习模型不同,深度学习模型实际上充满了超参数。
当然,并非所有变量对模型的学习过程都一样重要,但是,鉴于这种额外的复杂性,在这样一个高维空间中找到这些变量的最佳配置显然是一个不小的挑战。
幸运的是,我们有不同的策略和工具来解决搜索问题。开始深入!
一、我们的目的
1. 怎么做?
我们希望找到最佳的超参数配置,帮助我们在验证/测试集的关键度量上得到最佳分数。
2. 为何?
在计算力、金钱和时间资源有限的情况下,每个科学家和研究员都希望获得最佳模型。但是我们缺少有效的超参数搜索来实现这一目标。
3. 何时?
研究员和深度学习爱好者在最后的开发阶段尝试其中一种搜索策略很常见。这有助于从经过几个小时的训练获得的最佳模型中获得可能的提升。
超参数搜索作为半/全自动深度学习网络中的阶段或组件也很常见。显然,这在公司的数据科学团队中更为常见。
等等,究竟何谓超参数?
我们从最简单的定义开始,
超参数是你在构建机器/深度学习模型时可以调整的「旋钮」。
将超参数比作「旋钮」或「拨号盘」
或者:
超参数是在开始训练之前手动设置的具有预定值的训练变量。超参数是在开始训练之前手动设置的具有预定值的训练变量。
我们可能会同意学习率和 Dropout 率是超参数,但模型设计变量呢?模型设计变量包括嵌入,层数,激活函数等。我们应该将这些变量视为超参数吗?
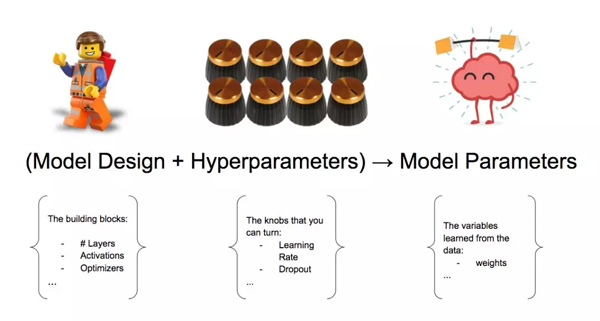
模型设计变量+超参数→模型参数
简单起见,我们也可以将模型设计组件视为超参数集的一部分。
最后,从训练过程中获得的参数(即从数据中学习的变量)算超参数吗?这些权重称为模型参数。我们不将它们算作超参数。
好的,让我们看一个真实的例子。请看下面的图片,仅以此图说明深度学习模型中变量的不同分类。
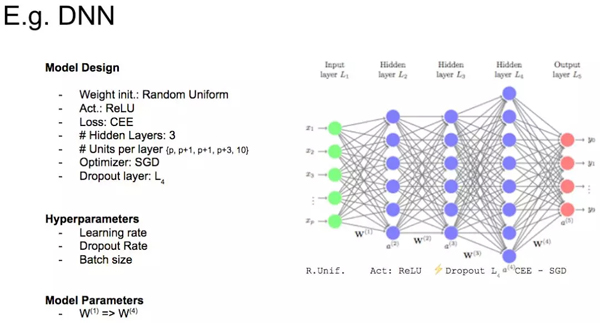
变量类别示例图
4. 下一个问题:搜索代价高昂
我们已经知道,我们的目标是搜索超参数的最佳配置,但超参数搜索本质上是一个受计算能力、金钱和时间约束的迭代过程。

超参数搜索周期
一切都以猜测一个不错的配置开始(步骤 1),然后我们需要等到训练完毕(步骤 2)以获得对相关度量标准的实际评估(步骤 3)。我们将跟踪搜索过程的进度(步骤 4),然后根据我们的搜索策略选择一个新的猜测参数(步骤 1)。
我们一直这样做,直到达到终止条件(例如用完时间或金钱)。
我们有四种主要的策略可用于搜索最佳配置。
照看(babysitting,又叫试错)
网格搜索
随机搜索
贝叶斯优化
二、照看
照看法被称为试错法或在学术领域称为研究生下降法。这种方法 100% 手动,是研究员、学生和业余爱好者最广泛采用的方法。
该端到端的工作流程非常简单:学生设计一个新实验,遵循学习过程的所有步骤(从数据收集到特征图可视化),然后她按顺序迭代超参数,直到她耗尽时间(通常是到截止日期)或动机。
")
照看(babysitting)
如果你已经注册了 deeplearning.ai 课程,那么你一定熟悉这种方法 - 这是由 Andrew Ng 教授提出的熊猫工作流程。
这种方法非常有教育意义,但它不能在时间宝贵的数据科学家的团队或公司内部施展。
因此,我们遇到这个问题:有更好的方式来增值我的时间吗?
肯定有!我们可以定义一个自动化的超参数搜索程序来节约你的时间。
三、网格搜索
取自命令式指令「Just try everything!」的网格搜索——一种简单尝试每种可能配置的朴素方法。
工作流如下:
定义一个 n 维的网格,其中每格都有一个超参数映射。例如 n = (learning_rate, dropout_rate, batch_size)
对于每个维度,定义可能的取值范围:例如 batch_size = [4,8,16,32,64,128,256 ]
搜索所有可能的配置并等待结果去建立最佳配置:例如 C1 = (0.1, 0.3, 4) -> acc = 92%, C2 = (0.1, 0.35, 4) -> acc = 92.3% 等...
下图展示了包含 Dropout 和学习率的二维简单网格搜索。

两变量并发执行的网格搜索




;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}