安全开发之扫描器迭代记:W9Scan
作者:媒体转发 时间:2018-02-25 09:17
w9scan是一款全能型的网站漏洞扫描器,借鉴了各位前辈的优秀代码。内置1200+插件可对网站进行一次规模的检测,功能包括但不限于web指纹检测、端口指纹检测、网站结构分析、各种流行的漏洞检测、爬虫以及SQL注入检测、XSS检测等等,w9scan会自动生成精美HTML格式结果报告。
在开发w9scan之前笔者已经开发过了w8scan,了解的朋友可能知道,w8scan的扫描功能并不强,所以,笔者想通过开发w9scan,这款在本地运行的扫描器来为w8scan的扫描器代码探路~。
俗话说工欲善其事必先利其器,笔者用过很多扫描器,无不为他们强大的扫描功能所折服。而笔者作为一名脚本小子,本想开车驶向远方却造起了轮子乐此不疲。仅以此文纪念w9scan的开发过程,纪念那逝去的青春…
额,,, 将视线拉回到本渣作。w9scan的初期代码是模仿bugscan而写的,因为w9scan在编写的初期就是为了兼容bugscan的插件,因此做了大量兼容工作来兼容w9scan的代码。而做兼容工作必不可少要了解下bugscan的工作原理,所以笔者用自己的渣渣理解力简述下bugscan的功能流程:
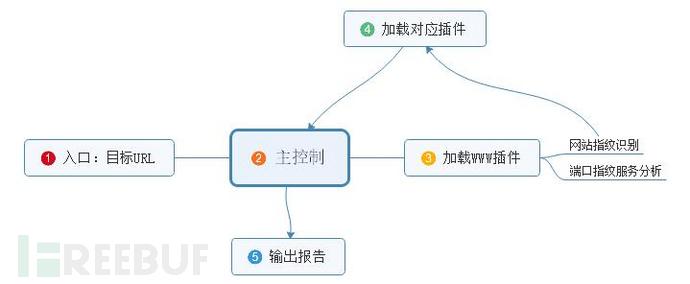
首先加载服务类型为www的插件,www插件扫描的过程中同时解析服务,得到ip,加载服务类型为ip的插件继续扫描,得到端口信息加载各种端口插件对目标分析,得到CMS信息,加载对应cms的插件等等…
不得不说,这是一个很棒的结构。
于是笔者在代码结构层次模仿w9scan,功能结构层次模仿bugscan,凭着脑中若干的想像!@#¥@# 制造了w9scan第一版本..
对于bugscan插件的兼容:可以在
lib/code/exploit.pyExploit_run类中找到,主要通过下面几个阶段完成。
1. 获取plugins目录下所有的py文件,(__init__.py除外),将内容存入一个字典中
2. 插件代码加载函数,通过调用imp模块将字典存储的代码加载进来,返回模块对象
def_load_module(self,chunk,name='<w9scan>'): try: pluginObj = imp.new_module(str(name)) exec chunk in pluginObj.__dict__ except Exception as err_info: raise LoadModuleException return pluginObj3.为返回的模块类加上内置的API(就是一些bugscan常用的内置API,如curlhackhttp之类)

4.一切就绪,然后根据bugscan API说明,bugscan插件需定义两个函数 assign为验证 audit为执行函数。所有接下来来调用这两个函数了。
pluginObj_tuple = pluginObj.assign(service,url) if notisinstance(pluginObj_tuple, tuple): # 判断是否是元组 continue bool_value, agrs =pluginObj_tuple[0], pluginObj_tuple[1] if bool_value: pluginObj.audit(agrs) CMS识别目前CMS大多数都是依靠指纹,看了很多依靠机器识别来验证webshell的列子,笔者也在学习如何用机器学习来识别CMS。
W9scan的CMS识别的指纹库以及代码都是bugscan的,里面有一些有趣的技巧,分享一下。CMS指纹文件在 lib/utils/cmsdata.py

可以看到主要是根据MD5以及关键字来识别的。笔者之前写的CMS识别都会用个字段来表示识别方式,这个似乎没有,来看看有什么奥秘?
来到 plugins/www/whatcms.py
import re,urlparse from lib.utils.cmsdata import cms_dict import hashlib def getMD5(password): m= hashlib.md5() m.update(password) return m.hexdigest() def makeurl(url): prox = "http://" if(url.startswith("https://")): prox = "https://" url_info = urlparse.urlparse(url) url = prox + url_info.netloc + "/" return url def isMatching(f_path, cms_name, sign, res,code, host, head): isMatch = False if f_path.endswith(".gif"): if sign: isMatch = getMD5(res) == sign else: isMatch = res.startswith("GIF89a") elif f_path.endswith(".png"): if sign: isMatch = getMD5(res) == sign else: isMatch = res.startswith("\x89PNG\x0d\x0a\x1a\x0a") elif f_path.endswith(".jpg"): if sign: isMatch = getMD5(res) == sign else: isMatch = res.startswith("\xff\xd8\xff\xe0\x00\x10JFIF") elif f_path.endswith(".ico"): if sign: isMatch = getMD5(res) == sign else: isMatch = res.startswith("\x00\x00\x00") elif code == 200: if sign and res.find(sign) != -1 or head.find(sign) != -1: isMatch = True elif sign and head.find(sign) != -1: isMatch = True if isMatch: task_push(cms_name, host, target=util.get_url_host(host)) security_note(cms_name,'whatcms') #print "%s %s" % (cms_name, host) return True return False def assign(service, arg): if service == "www": return True,makeurl(arg) def audit(arg): cms_cache = {} cache = {} def _cache(url): if url in cache: return cache[url] else: status_code, header, html_body, error, error = curl.curl2(url) if status_code != 200 or not html_body: html_body = "" cache[url] = (status_code, header, html_body) return status_code, header, html_body for cmsname in cms_dict: cms_hash_list = cms_dict[cmsname] for cms_hash in cms_hash_list: if isinstance(cms_hash, tuple): f_path, sign = cms_hash else: f_path, sign = cms_hash, None if not isinstance(f_path, list): f_path = [f_path] for file_path in f_path: if file_path not in cms_cache: cms_cache[file_path] = [] cms_cache[file_path].append((cmsname, sign)) cms_key = cms_cache.keys() cms_key.sort(key=len) isMatch = False for f_path in cms_key: if isMatch: break for cms_name, sign in cms_cache[f_path]: code, head, res = _cache(arg + f_path) isMatch =isMatching(f_path, cms_name, sign, res, code, arg, head) if isMatch: break



;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}