Apache Flink 漫谈系列 - 概述
作者:CQITer小编 时间:2018-09-26 21:07
一、Apache Flink 的命脉
"命脉" 即生命与血脉,常喻极为重要的事物。系列的首篇,首篇的首段不聊Apache Flink的历史,不聊Apache Flink的架构,不聊Apache Flink的功能特性,我们用一句话聊聊什么是 Apache Flink 的命脉?我的答案是:Apache Flink 是以"批是流的特例"的认知进行系统设计的。
二、唯快不破
我们经常听说 "天下武功,唯快不破",大概意思是说 "任何一种武功的招数都是有拆招的,唯有速度快,快到对手根本来不及反应,你就将对手KO了,对手没有机会拆招,所以唯快不破"。 那么这与Apache Flink有什么关系呢?Apache Flink是Native Streaming(纯流式)计算引擎,在实时计算场景最关心的就是"快",也就是 "低延时"。
就目前最热的两种流计算引擎Apache Spark和Apache Flink而言,谁最终会成为No1呢?单从 "低延时" 的角度看,Spark是Micro Batching(微批式)模式,最低延迟Spark能达到0.5~2秒左右,Flink是Native Streaming(纯流式)模式,最低延时能达到微秒。很显然是相对较晚出道的 Apache Flink 后来者居上。 那么为什么Apache Flink能做到如此之 "快"呢?根本原因是Apache Flink 设计之初就认为 "批是流的特例",整个系统是Native Streaming设计,每来一条数据都能够触发计算。相对于需要靠时间来积攒数据Micro Batching模式来说,在架构上就已经占据了绝对优势。
那么为什么关于流计算会有两种计算模式呢?归其根本是因为对流计算的认知不同,是"流是批的特例" 和 "批是流的特例" 两种不同认知产物。
1. Micro Batching 模式
Micro-Batching 计算模式认为 "流是批的特例", 流计算就是将连续不断的批进行持续计算,如果批足够小那么就有足够小的延时,在一定程度上满足了99%的实时计算场景。那么那1%为啥做不到呢?这就是架构的魅力,在Micro-Batching模式的架构实现上就有一个自然流数据流入系统进行攒批的过程,这在一定程度上就增加了延时。具体如下示意图:

很显然Micro-Batching模式有其天生的低延时瓶颈,但任何事物的存在都有两面性,在大数据计算的发展历史上,最初Hadoop上的MapReduce就是优秀的批模式计算框架,Micro-Batching在设计和实现上可以借鉴很多成熟实践。
2. Native Streaming 模式
Native Streaming 计算模式认为 ""批是流的特例",这个认知更贴切流的概念,比如一些监控类的消息流,数据库操作的binlog,实时的支付交易信息等等自然流数据都是一条,一条的流入。Native Streaming 计算模式每条数据的到来都进行计算,这种计算模式显得更自然,并且延时性能达到更低。具体如下示意图:

很明显Native Streaming模式占据了流计算领域 "低延时" 的核心竞争力,当然Native Streaming模式的实现框架是一个历史先河,第一个实现Native Streaming模式的流计算框架是第一个吃螃蟹的人,需要面临更多的挑战,后续章节我们会慢慢介绍。当然Native Streaming模式的框架实现上面很容易实现Micro-Batching和Batching模式模式的计算,Apache Flink就是Native Streaming计算模式的流批统一的计算引擎。
三、丰富的部署模式
Apache Flink 按不同的需求支持Local,Cluster,Cloud三种部署模式,同时Apache Flink在部署上能够与其他成熟的生态产品进行完美集成,如 Cluster模式下可以利用YARN(Yet Another Resource Negotiator)/Mesos集成进行资源管理,在Cloud部署模式下可以与GCE(Google Compute Engine), EC2(Elastic Compute Cloud)进行集成。
1. Local 模式
该模式下Apache Flink 整体运行在Single JVM中,在开发学习中使用,同时也可以安装到很多端类设备上。
2. Cluster模式
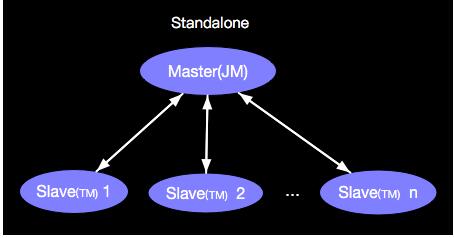
该模式是典型的投产的集群模式,Apache Flink 既可以Standalone的方式进行部署,也可以与其他资源管理系统进行集成部署,比如与YARN进行集成。
这种部署模式是典型的Master/Slave模式,我们以Standalone Cluster模式为例示意如下:



;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}