如何用Python做自动化特征工程
作者:CQITer小编 时间:2018-09-05 16:28

大数据文摘出品
编译:张弛、倪倪、笪洁琼、夏雅薇
机器学习的模型训练越来越自动化,但特征工程还是一个漫长的手动过程,依赖于专业的领域知识,直觉和数据处理。而特征选取恰恰是机器学习重要的先期步骤,虽然不如模型训练那样能产生直接可用的结果。本文作者将使用Python的featuretools库进行自动化特征工程的示例。
机器学习越来越多地从手动设计模型转变为使用H20,TPOT和auto-sklearn等工具来自动优化的渠道。这些库以及随机搜索等方法旨在通过查找数据集的最优模型来简化模型选择和转变机器学习的部分,几乎不需要人工干预。然而,特征工程几乎完全是人工,这无疑是机器学习管道中更有价值的方面。
特征工程也称为特征创建,是从现有数据构建新特征以训练机器学习模型的过程。这个步骤可能比实际应用的模型更重要,因为机器学习算法只从我们提供的数据中学习,然而创建与任务相关的特征绝对是至关重要的。
通常,特征工程是一个漫长的手动过程,依赖于专业的领域知识,直觉和数据处理。这个过程可能非常繁琐,而且最终的特征将受到人类主观性和时间的限制。自动化特征工程旨在通过从数据集中自动创建许多候选特征来帮助数据科学家,并从中可以选择最佳特征用于训练。
在本文中,我们将使用Python 的featuretools库进行自动化特征工程的示例。我们将使用示例数据集来演示基础知识。
完整代码:
https://github.com/WillKoehrsen/automated-feature-engineering/blob/master/walk_through/Automated_Feature_Engineering.ipynb
一、特征工程基础
特征工程意味着从现有数据中构建额外特征,这些数据通常分布在多个相关表中。特征工程需要从数据中提取相关信息并将其放入单个表中,然后可以使用该表来训练机器学习模型。
构建特征的过程非常地耗时,因为每个特征的构建通常需要一些步骤来实现,尤其是使用多个表中的信息时。我们可以将特征创建的步骤分为两类:转换和聚合。让我们看几个例子来了解这些概念的实际应用。
转换作用于单个表(从Python角度来看,表只是一个Pandas 数据框),它通过一个或多个现有的列创建新特征。
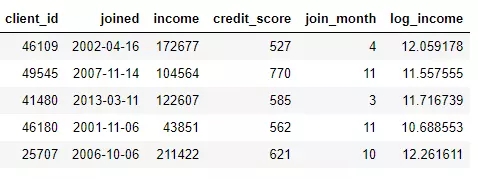
例如,如果我们有如下客户表。

我们可以通过查找joined列的月份或是获取income列的自然对数来创建特征。这些都是转换,因为它们仅使用来自一个表的信息。
import pandas as pd
# Group loans by client id and calculate mean, max, min of loans
stats = loans.groupby('client_id')['loan_amount'].agg(['mean', 'max', 'min'])
stats.columns = ['mean_loan_amount', 'max_loan_amount', 'min_loan_amount']
# Merge with the clients dataframe
stats = clients.merge(stats, left_on = 'client_id', right_index=True, how = 'left')
stats.head(10)
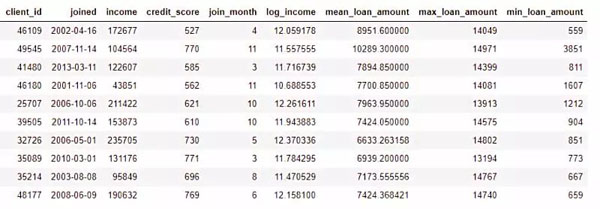
另一方面,聚合作用于多个表,并使用一对多的关系对观测值进行分组,然后计算统计数据。例如,如果我们有另一个包含客户贷款的信息表格,其中每个客户可能有多笔贷款,我们可以计算每个客户的贷款的平均值,最大值和最小值等统计数据。
此过程包括通过客户信息对贷款表进行分组,计算聚合,然后将结果数据合并到客户数据中。以下是我们如何使用Pandas库在Python中执行此操作。




;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}