从技术角度聊聊,短视频为何让人停不下来?
作者:网友投稿 时间:2018-08-28 09:28

基于时间碎片化、视频交互强、内容丰富、体验好等因素,短视频近几年处在流量风暴的中心,各大平台纷纷涉足短视频领域。因此,平台对短视频内容的推荐尤为重要,千人千面是短视频推荐核心竞争力。短视频一般从“点击率”与“观看时长”两方面优化来提升用户消费时长。
接下来,UC事业部国际研发团队的童鞋,将从这两方面重点论述短视频模型点击时长多目标优化。
背景
目前,信息流短视频排序是基于CTR预估Wide&Deep深层模型。在Wide&Deep模型基础上做一系列相关优化,包括相关性与体感信号引入、多场景样本融合、多模态学习、树模型等,均取得不错收益。
总体上,短视频模型优化可分为两部分优化:
感知相关性优化——点击模型以优化(CTR/Click为目标)
真实相关性优化——时长多目标优化(停留时长RDTM/播放完成率PCR)
上述收益均基于点击模型的优化,模型能够很好地捕抓USER-ITEM之间感知相关性,感知权重占比较高,弱化真实相关性,这样可能导致用户兴趣收窄,长尾问题加剧。此外,观看时长,无论是信息流、竞品均作为重要优化目标。在此背景下,短视频排序模型迫切需要引入时长多目标优化,提升推荐的真实相关性,寻求在时长上取得突破。
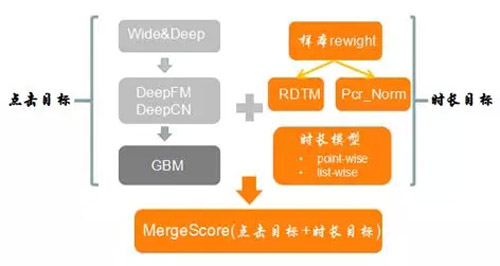
时长多目标的引入,排序模型不仅仅优化点击目标,同时也要兼顾时长目标,使得排序模型的感知相关性与真实相关性之间取得收益最大化的平衡;目前业界点击+时长目标优化有多种方式,包括多模态学习(点击+时长)、联合建模、样本reweight等。
本次我们使用样本reweight方法,在点击label不变的前提下,时长作为较强的bias去影响时长目标,保证感知相关性前提,去优化真实相关性。此外,我们正调研更加自适应的时长建模方式(point-wise、list-wise),后续继续介绍。上述是模型时长多目标优化简介,样本reweight取得不错的收益,下面展开介绍下。
RDTM REWEIGHTING
观看时长加权优化,我们使用weightlogistic regression方法,参照RecSys2016上Youtubb时长建模,提出点击模型上样本reweight。模型训练时,通过观看时长对正样本加权,负样本权重不变,去影响正负样本的权重分布,使得观看时长越长的样本,在时长目标下得到充分训练。
加权逻辑回归方法在稀疏点击场景下可以很好使得时长逼近与期望值。假设就是weighted logistic regression学到的期望,其中N是样本数量,K是正样本,Ti是停留时长,真实期望就近似逼近E(T)*(1+P),P是点击概率,E(T)是停留时长期望值,在P<<1情况下,真实期望值就逼近E(T)。因此,加权逻辑回归方式做样本加权,切合我们点击稀疏的场景,通过样本加权方式使得模型学到item在观看时长上偏序关系。

样本加权优化我们参照了Youtube的时长建模,但做法上又存在一些差异:
Label:Youtube以时长为label做优化,而我们还是基于点击label,这样是为了保证模型感知相关性(CTR/Click)。
分类/回归:Youtube以回归问题作时长加权,serving以指数函数拟合时长预测值,我们则是分类问题,优化损失函数logloss,以时长bias优化时长目标。
加权形式:时长加权方式上我们考虑观看时长与视频长短关系,采用多分段函数平滑观看时长和视频长短关系,而youtube则是观看时长加权。
上述差异主要从两个方面考虑:
保证CTR稳定的前提下(模型label依然是点击),通过样本reweight去优化时长目标。
分段函数平滑避免长短视频的下发量严重倾斜,尽可能去减少因为视频长短因素,而使模型打分差距较大问题。
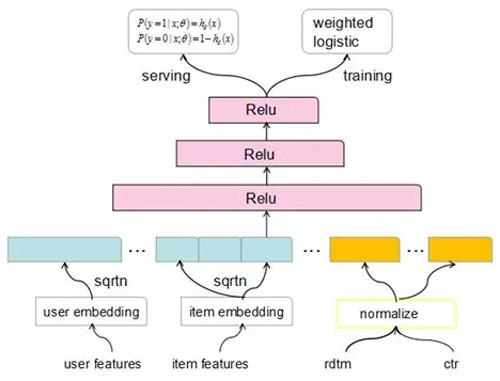
在模型网络结构上,底层类目或内容特征做embedding共享,连续特征离散归一化。训练时通过引入weighted logistic去优化时长目标,在线预测依然是0/1概率,而在0/1概率跟之前不同是的经过时长bias修正,使得模型排序考虑真实相关性。
离线评估指标
1、AUC:AUC作为排序模型常用离线评估特别适用是0/1分类问题,短视频排序模型依然是0/1问题,所以,AUC是一个基础离线指标。此外,AUC很难准确地评估模型对于时长优化好坏,AUC只是作为模型准入的条件,保证AUC持平/正向前提下,我们需要时长指标衡量准确地模型收益。




;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}