一文解读合成数据在机器学习技术下的表现
作者:CQITer小编 时间:2018-08-24 09:23

作者:Eric Le Fort
编译:蒋雨畅 卢苗苗
想法
相比于数量有限的“有机”数据,我将分析、测评合成数据是否能实现改进。
动机
我对合成数据的有效性持怀疑态度——预测模型只能与用于训练数据的数据集一样好。这种怀疑论点燃了我内心的想法,即通过客观调查来研究这些直觉。
需具备的知识
本文的读者应该处于对机器学习相关理论理解的中间水平,并且应该已经熟悉以下主题以便充分理解本文:
基本统计知识,例如“标准差”一词的含义
熟悉神经网络,SVM和决策树(如果您只熟悉其中的一个或两个,那可能就行了)
了解基本的机器学习术语,例如“训练/测试/验证集”的含义
合成数据的背景
生成合成数据的两种常用方法是:
根据某些分布或分布集合绘制值
个体为本模型的建模
在这项研究中,我们将检查第一类。为了巩固这个想法,让我们从一个例子开始吧!
想象一下,在只考虑大小和体重的情况下,你试图确定一只动物是老鼠,青蛙还是鸽子。但你只有一个数据集,每种动物只有两个数据。因此不幸的是,我们无法用如此小的数据集训练出好的模型!
这个问题的答案是通过估计这些特征的分布来合成更多数据。让我们从青蛙的例子开始
参考这篇维基百科的文章(只考虑成年青蛙):https://en.wikipedia.org/wiki/Common_frog
第一个特征,即它们的平均长度(7.5cm±1.5cm),可以通过从正态分布中绘制平均值为7.5且标准偏差为1.5的值来生成。类似的技术可用于预测它们的重量。
然而,我们所掌握的信息并不包括其体重的典型范围,只知道平均值为22.7克。一个想法是使用10%(2.27g)的任意标准偏差。不幸的是,这只是纯粹猜测的结果,因此很可能不准确。
鉴于与其特征相关信息的可获得性,和基于这些特征来区分物种的容易程度,这可能足以培养良好的模型。但是,当您迁移到具有更多特征和区别更细微的陌生系统时,合成有用的数据变得更加困难。
数据
该分析使用与上面讨论的类比相同的想法。我们将创建一些具有10个特征的数据集。这些数据集将包含两个不同的分类类别,每个类别的样本数相同。
“有机”数据
每个类别将遵循其中每个特征的某种正态分布。例如,对于第一种特征:第一个类别样本的平均值为1500,标准差为360;第二个类别样本的平均值为1300,标准差为290。其余特征的分布如下:

该表非常密集,但可以总结为:
有四个特征在两类之间几乎无法区分,
有四个特征具有明显的重叠,但在某些情况下应该可以区分,并且
有两个特征只有一些重叠,通常是可区分的。
创建两个这样的数据集,一个1000样本的数据集将保留为验证集,另一个1000样本的数据集可用于训练/测试。
这会创建一个数据集,使分类变得足够强大。
合成数据
现在事情开始变得有趣了!合成数据将遵循两个自定义分布中的其中一个。第一个我称之为“ Spikes Distribution”。此分布仅允许合成特征采用少数具有每个值的特定概率的离散值。例如,如果原始分布的平均值为3且标准差为1,则尖峰(spike)可能出现在2(27%),3(46%)和4(27%)。
第二个自定义分布我称之为“ Plateaus Distribution”。这种分布只是分段均匀分布。使用平台中心的正态分布概率推导出平稳点的概率。您可以使用任意数量的尖峰或平台,当添加更多时,分布将更接近正态分布。
为了清楚说明这两个分布,可以参考下图:
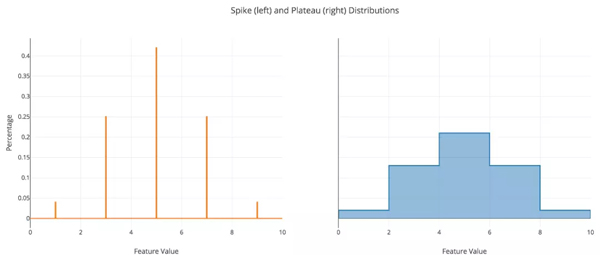
(注:尖峰分布图不是概率密度函数)
在这个问题中,合成数据的过程将成为一个非常重要的假设,它有利于使合成数据更接近于“有机”数据。该假设是每个特征/类别对的真实平均值和标准差是已知的。实际上,如果合成数据与这些值相差太远,则会严重影响训练模型的准确性。
好的,但为什么要使用这些分布?他们如何反映现实?
我很高兴你问这个问题!在有限的数据集中,您可能会注意到,对于某个类别,某个特征只会占用少量值。想象一下这些值是:
(50,75,54,49,24,58,49,64,43,36)
或者如果我们可以对这列进行排序:
(24,36,43,49,49,50,54,58,64,75)



;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}