多级缓存设计详解 | 给数据库减负,刻不容缓!
作者:CQITer小编 时间:2018-08-23 09:04
自古兵家多谋,《谋攻篇》,“故上兵伐谋,其次伐交,其次伐兵,其下攻城。攻城之法,为不得已”,可见攻城之计有很多种,而爬墙攻城是最不明智的做法,军队疲惫受损、钱粮损耗、百姓遭殃。故而我们有很多迂回之策,谋略、外交、军事手段等等,每一种都比攻城的代价小,更轻量级,缓存设计亦是如此。

其实高并发应对的解决方案不是互联网独创的,计算机先祖们很早就对类似的场景做了方案。比如《计算机组成原理》这样提到的cpu缓存概念,它是一种高速缓存,容量比内存小但是速度却快很多,这种缓存的出现主要是为了解决cpu运算速度远大于内存读写速度,甚至达到千万倍。
传统的cpu通过fsb直连内存的方式显然就会因为内存访问的等待,导致cpu吞吐量下降,内存成为性能瓶颈。同时又由于内存访问的热点数据集中性,所以需要在cpu与内存之间做一层临时的存储器作为高速缓存。
随着系统复杂性的提升,这种高速缓存和内存之间的速度进一步拉开,由于技术难度和成本等原因,所以有了更大的二级、三级缓存。根据读取顺序,绝大多数的请求首先落在一级缓存上,其次二级...
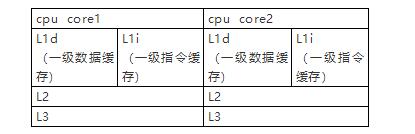
故而应用于SOA甚至微服务的场景,内存相当于存储业务数据的持久化数据库,其吞吐量肯定是远远小于缓存的,而对于java程序来讲,本地的jvm缓存优于集中式的redis缓存。
关系型数据库操作方便、易于维护且访问数据灵活,但是随着数据量的增加,其检索、更新的效率会越来越低。所以在高并发低延迟要求复杂的场景,要给数据库减负,减少其压力。
给数据库减负
1. 缓存分布式,做多级缓存

(1) 读请求时写缓存
写缓存时一级一级写,先写本地缓存,再写集中式缓存。具体些缓存的方法可以有很多种,但是需要注意几项原则:
不要复制粘贴,避免重复代码
切忌和业务耦合太紧,不利于后期维护
开发初期刚刚上线阶段,为了排查问题,常常会给缓存设置开关,但是开关设置多了则会同时升高系统的复杂度,需要结合一套统一配置管理系统,京东物流有一套叫做UCC,且听下回分解......

综上所述,高耦合带来的痛,弥补的代价是很大的,所以可以借鉴Spring cache来实现,实现也比较简单,使用时一个注解就搞定了。
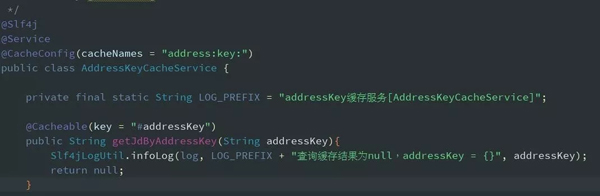
(2) 写缓存失败了怎么办?应该先写缓存还是数据库呢?
既然是缓存的设计,那么策略一定是保证最终一致性,那么我们只需要采用异步消息来补偿就好了。
大部分缓存应用的场景是读写比差异很大的,读远大于写,在这种场景下,只需要以数据库为主,先写数据库,再写缓存就好了。
最后补充一点,数据库出现异常时,不要一股脑的catch RuntimeException,而是把具体关心的异常往外抛,然后进行有针对性的异常处理。
(3) 关于其他性能方面
缓存设计都是占用越少越好,内存资源昂贵以及太大不好维护都驱使我们这样设计。所以要尽可能减少缓存不必要的数据,有的同学图省事把整个对象序列化存储。另外,序列化与反序列化也是消耗性能的。
2. vs各种缓存同步方案
缓存同步方案有很多种,在考虑一致性、数据库访问压力、实时性等方面做权衡。总的来说有以下几种方式:
(1) 懒加载式
如上段提到的方式,读时顺便加载。为了更新缓存数据,需要过期缓存。

优点:简单直接
缺点:
会造成一次缓存不命中
这样当用户并发很大时,恰好缓存中无数据,数据库承担瞬时流量过大会造成风险。
懒加载式太简单了,没有自动加载,异步刷新等机制,为了弥补其缺陷,请参见接下来的两种方法。
(2) 补充式




;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}