从DevOps到AIOps,阿里如何实现智能化运维?
作者:媒体转发 时间:2018-08-12 01:05

背景
随着搜索业务的快速发展,搜索系统都在走向平台化,运维方式在经历人肉运维,脚本自动化运维后最终演变成DevOps。但随着大数据及人工智能的快速发展,传统的运维方式及解决方案已不能满足需求。
基于如何提升平台效率和稳定性及降低资源,我们实现了在线服务优化大师hawkeye及容量规划平台torch。经过几年的沉淀后,我们在配置合理性、资源合理性设置、性能瓶颈、部署合理性等4个方面做了比较好的实践。下面具体介绍下hawkeye和torch系统架构及实现。
AIOps实践及实现
hawkeye——智能诊断及优化
系统简介
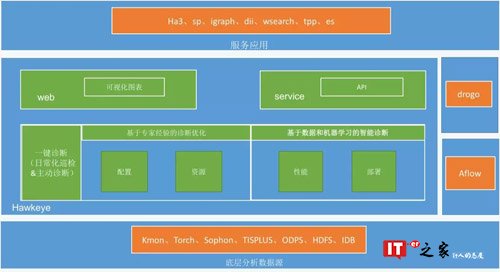
hawkeye是一个智能诊断及优化系统,平台大体分为三部分:
1.分析层,包括两部分:
1) 底层分析工程hawkeye-blink:基于Blink完成数据处理的工作,重点是访问日志分析、全量数据分析等,该工程侧重底层的数据分析,借助Blink强大的数据处理能力,每天对于搜索平台所有Ha3应用的访问日志以及全量数据进行分析。
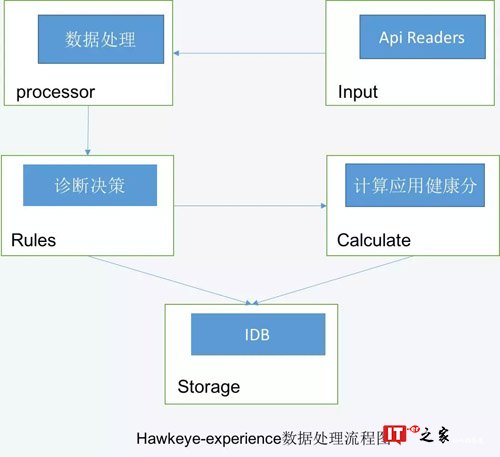
2) 一键诊断工程hawkeye-experience:基于hawkeye-blink的分析结果进行更加贴近用户的分析,比如字段信息监测,包括字段类型合理性,字段值单调性监测等,除此之外还包括但不限于kmon无效报警、冒烟case录入情况、引擎降级配置、内存相关配置、推荐行列数配置以及切换时最小服务行比例等检测。
hawkeye-experience工程的定位是做一个引擎诊断规则中台,将平时运维人员优化维护引擎的宝贵经验沉淀到系统中来,让每一个新接入的应用可以快速享受这样的宝贵经验,而不是通过一次次的踩坑之后获得,让每位用户拥有一个类似智能诊断专家的角色来优化自己的引擎是我们的目标,也是我们持续奋斗的动力,其中hawkeye-experience的数据处理流程图如下所示:
2.web层:提供hawkeye分析结果的各种api以及可视化的监控图表输出。
3.service层:提供hawkeye分析与优化api的输出。
基于上述架构我们落地的诊断及优化功能有:
资源优化:引擎Lock内存优化(无效字段分析)、实时内存优化等;
性能优化:TopN慢query优化、buildservice资源设置优化等;
智能诊断:日常化巡检、智能问答等。
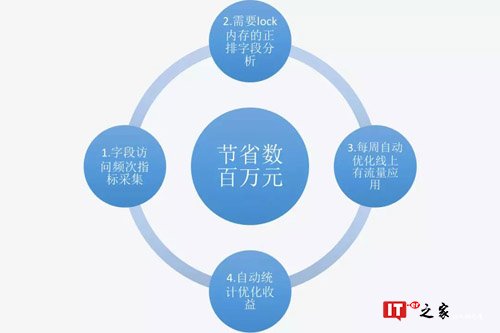
引擎Lock内存优化
对于Ha3引擎,引擎字段是分为倒排(index)索引、正排(attribute)索引和摘要(summary)索引的。引擎的Lock策略可以针对这三类索引进行Lock或者不Lock内存的设置,Lock内存好处不言而喻,加速访问,降低rt,但是试想100个字段中,如果两个月只有50个访问到了,其他字段在索引中压根没访问,这样会带来宝贵内存的较大浪费,为此hawkeye进行了如下分析与优化,针对头部应用进行了针对性的索引瘦身。下图为Lock内存优化的过程,累计节省约数百万元。
慢query分析
慢query数据来自应用的访问日志,query数量和应用的访问量有关,通常在千万甚至亿级别。从海量日志中获取TopN慢query属于大数据分析范畴。我们借助Blink的大数据分析能力,采用分治+hash+小顶堆的方式进行获取,即先将query格式进行解析,获取其查询时间,将解析后的k-v数据取md5值,然后根据md5值做分片,在每一个分片中计算TopN慢query,最后在所有的TopN中求出最终的TopN。对于分析出的TopN慢query提供个性化的优化建议给用户,从而帮助用户提升引擎查询性能,间接提高引擎容量。
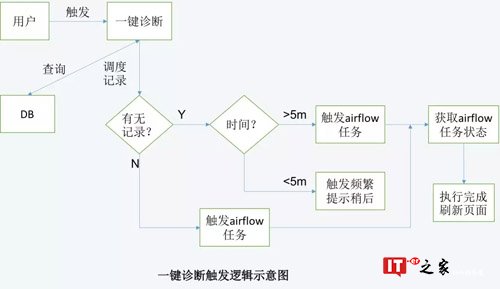
一键诊断
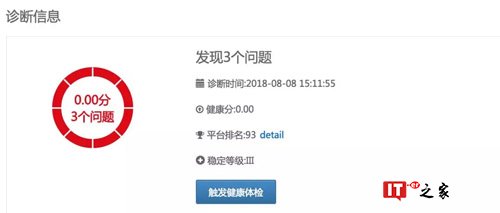
我们通过健康分衡量引擎健康状态,用户通过健康分可以明确知道自己的服务健康情况,诊断报告给出诊断时间,配置不合理的简要描述以及详情,优化的收益,诊断逻辑及一键诊断之后有问题的结果页面如下图所示,其中诊断详情页面因篇幅问题暂未列出。
智能问答



;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}