CNN取代RNN?当序列建模不再需要循环网络
作者:网友投稿 时间:2018-08-09 01:04
在过去几年中,虽然循环神经网络曾经一枝独秀,但现在自回归 Wavenet 或 Transformer 等模型在各种序列建模任务中正取代 RNN。而本文主要关注循环网络与前馈网络在序列建模中有什么差别,以及到底什么时候选择卷积网络替代循环网络比较好。
在这篇博文中,我们来探讨循环网络模型和前馈模型之间的取舍。前馈模型可以提高训练稳定性和速度,而循环模型表达能力更胜一筹。有趣的是,额外的表现力似乎并没有提高循环模型的性能。
一些研究团队已经证明,前馈网络可以达到最佳循环模型在基准序列任务上取得的结果。这种现象为理论研究提供了一个有趣的问题:
为什么前馈网络能够在不降低性能的前提下取代循环神经网络?什么时候可以取代?
我们讨论了几个可能的答案,并强调了我们最近的研究《When Recurrent Models Don't Need To Be Recurrent》,这项研究从基本稳定性的角度给出了解释。
一、两个序列模型的故事
1. 循环神经网络
循环模型的众多变体都具有类似的形式。该模型凭借状态 h_t 梳理过去的输入序列。在每个时间步 t,根据以下等式更新状态:
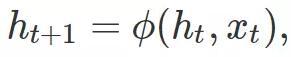
其中 x_t 是时刻 t 的输入,φ 是可微分映射,h_0 是初始状态。在一个最原始循环神经网络中,该模型由矩阵 W 和 U 参数化,并根据下式更新状态:
实践中,长短期记忆网络(LSTM)更常用。不管哪种情况,进行预测时,都将状态传递给函数 f,模型预测 y_t = f(h_t)。由于状态 h_t 是包含所有过去输入 x_0,...,x_t 的函数,因此预测 y_t 也取决于整个历史输入 x_0,...,x_t。
循环模型可用图形表示如下。

循环模型可以使用反向传播拟合数据。然而,从时间步 T 到时间步 0 反向传播的梯度通常需要大量难以满足的内存,因此,事实上每个循环模型的代码实现都会进行截断处理,并且只反向传播 k 个时间步的梯度。

按照这个配置,循环模型的预测仍然依赖于整个历史输入 x_0,…,x_T。然而,目前尚不清楚这种训练过程对模型学习长期模式的能力有何影响,特别是那些需要 k 步以上的模式。
2. 自回归、前馈模型
自回归(autoregressive)模型仅使用最近的 k 个输入,即 x_t-k + 1,...,x_t 来预测 y_t,而不是依赖整个历史状态进行预测。这对应于强条件独立性假设。特别是,前馈模型假定目标仅取决于 k 个最近的输入。谷歌的 WaveNet 很好地说明了这个通用原则。

与 RNN 相比,前馈模型的有限上下文意味着它无法捕获超过 k 个时间步的模式。但是,使用空洞卷积等技术,可以使 k 非常大。
二、为何关注前馈模型?
一开始,循环模型似乎是比前馈模型更灵活、更具表现力的模型。毕竟,前馈网络提出了强条件独立性假设,而循环模型并没有加上这样的限制。不过即使前馈模型的表现力较差,仍有几个原因使得研究者可能更倾向于使用前馈网络。
并行化:卷积前馈模型在训练时更容易并行化,不需要更新和保留隐藏状态,因此输出之间没有顺序依赖关系。这使得我们可以在现代硬件上非常高效地实现训练过程。
可训练性:训练深度卷积神经网络是深度学习的基本过程,而循环模型往往更难以训练与优化。此外,为了有效并可靠地训练深度前馈网络,开发人员在设计架构和软件开发上已经付出了巨大的努力。
推理速度:在某些情况下,前馈模型可以更轻量,并且比类似的循环系统更快地执行推理。在其他情况下,特别是对于长序列问题,自回归推理是一个很大的瓶颈,需要大量的工程工作或聪明才智去克服。
三、前馈模型可以比循环模型表现更好
虽然看起来前馈模型的可训练性和并行化是以降低模型准确度为代价的,但是最近有一些例子表明,前馈网络在基准任务上实际上可以达到与循环网络相同的精度。




;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}