DeepSeek凭什么以远低于行业的成本,打造出媲美GPT-4o的顶尖模型?
作者:佚名 时间:2025-11-13 09:21
当下,AI这个领域变得越发喧闹嘈杂,四处众多大模型纷纷展示格外独特的风貌呢,然而真正有胆子全面开展开源,还丝毫不保留地把技术细节呈现给大家看的实在是极其罕见呀,深入探寻,深度求索这家从幻方量化诞生出来的AI公司,走出了与众不同的道路,实在让人忍不住产生赞赏之情呀 。
公司背景与定位
幻方量化于人工智能领域有着相当关键的布局,开展深度探寻以寻觅相关价值,自2023年创立之后,着重将焦点汇聚至通用人工智能底层技术的研究与开发之上,该公司凭借在算力基础设施方面长久的投入,构建起了规模较大的高性能计算集群,从而为其大模型训练营造出了坚实的基础条件。
和传统闭源模型厂商不一样,深度求索坚守开源道路,把它所研发的大语言模型以及相关技术工具,向学术界和产业界去进行开放,像这样的一种策略,明显降低了AI技术应用的门槛,致使更多开发者和企业能够依靠先进模型来开展二次开发,并达成商业化应用 。
核心模型特性

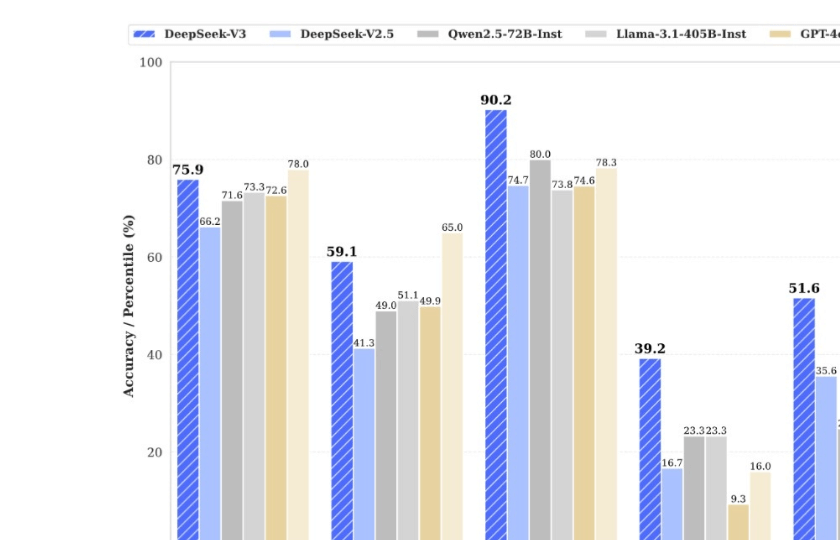
DeepSeek-V3模型运用混合专家架构,其激活参数量达六百七十亿,总参数量高达六千七百一十亿,它在众多基准测试里展现出同GPT-4相似的性能,于数学推理、代码生成领域有显著表现,在权威编程评测HumanEval上取得百分之九十点二的通过率。
全新发布的是DeepSeek-R1模型,它依凭引进“深度思考”机制,历经链式推理流程去处理复杂问题,由此形成强化推理能力,在它解答数学竞赛试题和国际科学奥林匹克各类题目时,其准确率跟前代相比有极为显著的提高,展现出强大的逻辑推理能力 。
技术创新亮点
存在一个名为DeepEP通信库的事物,它是深度求索自行研发出来的,针对混合专家模型具有的特性做了优化,实现了将节点间通信产生的开销降低的目的,而且降低的幅度超过了百分之四十,达成了这样的效果。它还与一个为MoE模型专门设计的DeepGEMM矩阵计算库协同配合,使得模型训练具备的效率提升了大约百分之三十,并且还大幅削减了训练所需的费用 。
公司处于并行计算范畴之中,创新性地提出了针对双向流水线的并行算法DualPipe,并且还把动态负载均衡工具EPLB与之进行了结合,切实有效地解决了大规模模型训练时计算资源处于被闲置状态的问题,这些技术突破将千亿参数模型训练成本控制在了行业平均水平的约60% 。
开源生态建设
投身深度探寻的深入开展,推动开源社区建设积极推进,借“开源周”项目完成核心技术模块按时发布。当中,3FS分布式文件系统对RDMA网络传输给予支持,借此达成达到100GB/s的读写吞吐量,为海量训练数据管理给予支持。
按照与之相关的情形配套推出的Smallpond数据处理框架,具备支持PB级别的数据集进行轻量处理的本事,在很大程度上让数据预处理流程得到淡化,这些工具采取开源举措,搞得研究机构和企业能够用快速方式构建起自身大模型训练环境。进而对整个行业的技术进步起到了推进作用呀。
功能应用场景
名为DeepSeek的一系列模型展现出广泛适用性,该模型在实际应用中,能在智能对话场景里准确理解用户意图,还能提供有价值的信息,在代码生成面上,它支持十余种编程语言代码自动补全,这十余种编程语言有Python、Java、C++等等,并且它还支持这十余种编程语言代码的错误检测 。
模型拥有联网搜索功能,能够实时获取最新信息用以辅助进行回答,在文本处理范畴,它可以完成内容分类工作,尚能够达成结构化输出工作,并且可执行多语言翻译等工作,进而为企业以及开发者给予全面的自然语言处理解决方案 。
使用与部署方案
DeepSeek因不同用户需求,给出灵活运用办法,个人用户能靠官方网页端与移动应用免费使用基础功能,企业用户可选择API接口集成或本地私有化部署,本地部署方案支持主流GPU硬件环境且保障数据安全与隐私保护。
官方同步公布了提示词库,其涵盖的领域有代码改写、内容创作、角色扮演等,这些都在13个核心应用场景中,用户能凭借优化提示词取得更为精准的模型输出,出现了这样的现象,这些资源显著降低了用户上手时面临的门槛,达成了模型使用效率的提升状况。
各类读者于运用各种有关AI的模型之际,最为看重的特性是哪些呢,是回应的速度,是回答的精准程度,还是功能的丰富程度呢,欢迎在评论区分享各类使用感受,要是觉得此篇文章有裨益,也请予以点赞予以支持哟!



;){kind=link}
底层技术研发,推出DeepSeek-V3和DeepSeek-R1等对标GPT-4o和OpenAI o1的模型。模型在推理、数学和编程能力上表现出色,训练成本低,应用广泛,涵盖智能对话、文本生成、代码生成等领域,并支持联网搜索与深度思考。DeepSeek提供本地部署选项,');){kind=link}
;){kind=link}
底层技术研发,推出DeepSeek-V3和DeepSeek-R1等对标GPT-4o和OpenAI o1的模型。模型在推理、数学和编程能力上表现出色,训练成本低,应用广泛,涵盖智能对话、文本生成、代码生成等领域,并支持联网搜索与深度思考。DeepSeek提供本地部署选项,');){kind=link}