还在为视频制作发愁?Colossyan的AI数字人竟然能帮你节省90%的时间和成本
作者:佚名 时间:2025-11-13 08:25
以从未有过的超快速度重塑内容创作生态的是AI视频生成技术,身为在科技领域持续深耕、进行观察的人,我们察觉到数字人技术已经从概念验证的阶段,迈进了达到规模化应用的前夕。Colossyan这类平台的出现并兴起,不但把视频制作的门槛给降低了,而且还预告了人机协作创作模式会变得常态化。
平台核心定位
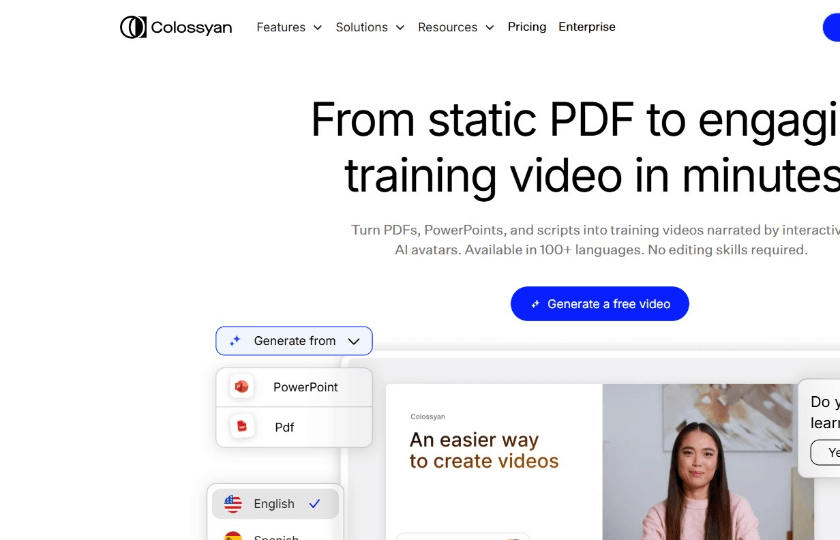
2023年刚冒头的AI视频生成平台Colossyan,它的核心功能是把静态文档转成动态视频,该平台能即时转换PDF、PPT以及文本脚本,还配备了有超过120种语言的语音合成系统,按照其官网数据表明,这样的转换 在原制作周期之上能压缩70%的时间。
该平台跟传统视频编辑软件不一样的特点是零基础操作设计的样式。用户不用掌握剪辑方面的技能,凭借拖拽式的界面就能够完成视频要素的相关配置。它的云端处理架构,有着支持实时渲染的功能,在普通网络的环境当中可以在5分钟之内生成1080P画质的视频对应的内容。
脚本处理机制
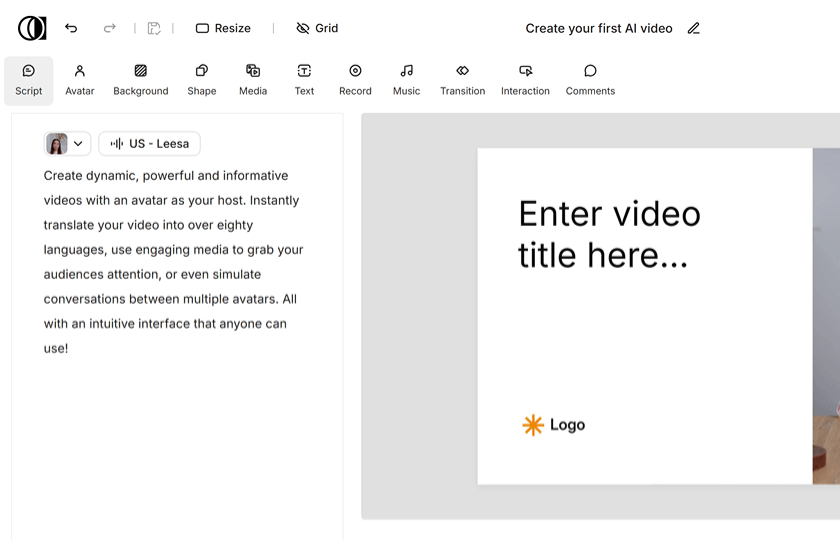
有的用户,在脚本编辑区域,能够分段去标注,不同角色的诸多对话内容。系统里,内置的语义识别分析引擎,能够自动识别语境,并且为不同段落,匹配对应的虚拟形象,进行发声。比如说,在技术培训场景当中,系统会把,专业术语集中的段落,自动分配至成熟稳重的数字人形象。
用于语音定制事宜的功能运用的是声纹克隆方面的技术,只要用户去上传超过3分钟时长的清晰的录音样本,就能够生成具备个人音色的数字发音库。此功能在2024年3月那次版本更新里增添了情感语调调节这一内容,进而让生成出来的语音更有表现力。
数字人形象库
平台给出包含各异年龄、职业特性的数字人模型,这些模型全凭借光学动作捕捉系统采集真实人类的表情数据创建,于商业应用场景里面,用户能够依照目标受众的地域特性选定具备当地面貌特征的虚拟形象。
配备超50种如挑眉、抿嘴等细微表情的微表情模板的是每个数字人形象,在最新版里,能依据脚本内容自动匹配相应手势从而让视频呈现更自然肢体语言的也是数字人 。
场景设计系统
含有教学演示、产品推介等八大类场景设计的内置智能模板库,当用户做出模板选择后,系统会依据脚本长度自动去分配镜头时长与转场效果,在自由设计模式里,支持精确到帧级的元素位置调整。
视觉元素库不断持续更新着,到2024年4月的时候就已经收录了超过一万种素材。这些素材全部都符合商业授权的标准,涵盖了不同风格的背景画面,还有信息图表以及动态图标,能够有效地避免版权方面的纠纷。
互动功能配置
特别适合培训场景的是,那在视频里嵌入选择题这种功能。编辑者能够在关键知识点那儿设置测试节点,系统就会记录观众做选择形成的数据,进而生成学习效果报告。分支路径功能有着这样的特性,它允许依据观众的选择向不同视频段落跳转 。
至用户后台,这些互动数据会实时反馈,以帮助企业量化培训效果。某制造业客户反馈,采用该功能后,员工培训考核通过率提升了34%,知识留存率提高到传统方式的2.1倍。
多语言处理能力
平台的机器翻译系统接入了神经网络引擎,它能在保持专业术语准确性的状况下,自动将语序调整得符合当地语言习惯。在生成非英语版本之际,系统会对数字人口型与字幕时序进行同步调整。
实际开展的测试呈现出这样的结果,把时长为 10 分钟的英文视频转化为西班牙语的版本,仅仅只需要 8 分钟的处理时长。这样的一项功能,能够让跨国企业在 24 小时之内,完成面向全球分支机构的培训视频本地化工作,大幅度地降低本地化的制作成本。
倘若AI数字人具备精准模仿人类表情以及声线的能力,您觉得这类技术最适宜应用于哪些特定的行业场景呢 ?欢迎于评论区分享您的见解 ,要是您认为本文存有参考价值 ,请不吝给予点赞支持 。




;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}