MMBench颠覆传统评测!你的多模态模型真的能通过这20项严苛测试吗?
作者:佚名 时间:2025-11-14 06:59
现今,多模态AI模型这般火爆,然而究竟哪一个才是真正地极具水准呢?MMBench的现身,使得这个问题拥有了更为明晰的答案。
MMBench基本构成
在2023年,上海人工智能实验室联合南洋理工大学、香港中文大学、新加坡国立大学以及浙江大学的那些展开研究的团队,推出了这样一个综合性评估基准,此基准涵盖了从互联网还有权威数据集中认认真真精选出来的大概约3000道单项选择题,这些题目的内容把日常生活、专业领域以及学术场景等方面尽数覆盖了。
这些题目参照从感知至认知的能力层级予以系统化组织,进而形成了20个拥有细粒度的评估维度,每个维度是针对特定能力而设计的,以此确保对模型性能展开全面检验,题目数量历经严格计算,得以保证统计显著性 。
评估方法创新
与传统那种基于规则匹配的评估方式不一样,MMBench引入了一种带有循环打乱选项的具有创新性的方法,这种方法在每一次进行测试的时候会随机去调整选项的顺序,它要求模型在多次测试的过程当中要保持答案的一致性,这样的一种设计能够有效地防止模型借助记忆或者是猜测来获取高分。
评估过程运用GPT来开展精准的答案匹配,把模型输出跟标准选项就语义层面予以比对,此方法被研究团队详述在2023年的技术报告中,大程度提升了评估的准确性与可靠性,规避了传统字符串匹配的局限性。
能力维度细分

涵盖多模态理解各个层面的MMBench的20项能力维度系统,基础感知层面包含物体识别、场景理解、文字识别等核心能力,认知层面涉及逻辑推理、因果关系、数值计算等高级智能表现。
每个能力的维度,都历经了严格的有关定义以及操作化处理,以此来保障评估所具有的针对性以及有效性。针对于此,研究形成的团队,参考了认知心理学领域以及人工智能领域里面现存的理论框架,并且结合实际应用时所产生的需求,进而建立起了这一具备完整性的评估体系。
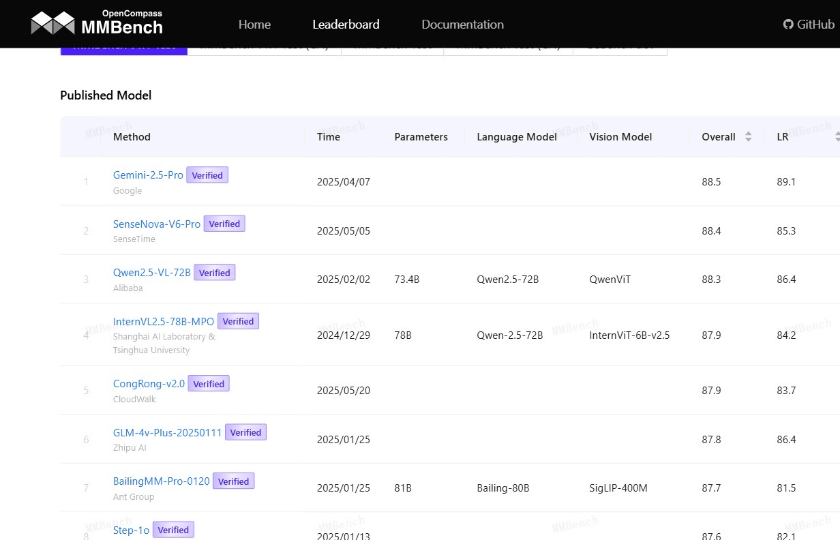
任务类型覆盖
该基准所包含的,是视觉问答、图像描述生成、视觉推理等诸多具有各类形式的任务种类,视觉问答这类任务,需要模型依据图像里所含的内容,去对文字问题作出回答,以此检验模型跨模态的理解能力,图像描述生成这一任务旨在评估模型从视觉方面的信息朝着语言方向表达方面转换所具备的质量。
于视觉推理任务里,模型得把图像信息跟常识知识相结合来开展逻辑推断。这些任务的设计体现了实际应用场景的需求,给模型性能评估提供了真实且有效的检验标准。
pip install vlmevalkit评估工具使用
研究团队同步开源了VLMEvalKit这个评估工具包,此工具是采用Python语言来开发的,它支持主流深度学习框架,用户能够通过简单的命令行接口进而对模型预测结果开展自动化评估,该工具会依照MMBench标准去计算诸如准确率这类核心指标。
wget <Download Link (VLMEvalKit)> -O MMBench_DEV_EN.zip
unzip MMBench_DEV_EN.zip首先,评估过程具备支持分布式计算的特性 ,这使得它能够以具备高效性的方式对大规模样式的测试数据予以处理呢。其次,研究人员能够在GitHub平台那里得到该工具的最新版本,因为工具包提供了有着详细阐述的使用文档以及示例代码呀。
结果提交与应用
from vlmeval.dataset import ImageMCQDataset
from vlmeval.smp import mmqa_display
# 加载 MMBench 开发集
dataset = ImageMCQDataset('MMBench_DEV_EN')
# 查看第 0 个样本
dataset.display(0)
# 构建多模态提示
item = dataset.build_prompt(0)
print(item)测试模型所获结果,能够借由官方平台予以提交,进而参与排行榜的排名。排行榜依据不同的模型架构、训练数据以及参数规模展开分类展示,并且每周更新一回。截止到2024年1月,已经有超过50个知名模型参与了评估。
此排名于学术界以及产业界给出了具备权威性的性能参照,直接体现出各个模型的技术水准,研究人员能够借助剖析并对比不一样模型的表现,辨识技术瓶颈且明确改进方向 。
各位从事开发工作的人员,于运用MMBench对自身所训练的模型展开评测期间,最为重视的究竟是哪一个能力层面所呈现出来的表现呢?欢迎在评论区域分享你所经历的测试体验之感,要是认为这篇撰文具备助益作用,请通过点赞的方式对我们予以支持!
python run.py --model llava_v1.5_7b --data MMBench_DEV_EN --mode infer



;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}