想避开大模型训练所有坑?这份200页避坑宝典为何让开发者疯狂追捧
作者:佚名 时间:2025-11-12 09:32
作为一名长时间聚焦AI技术演变的行业观察者而言我说注意到有越来越多的团队已经开始着手尝试自行研发大模型,然而在实际的落地进程之中被暴露出来的系统性欠缺是十分让人忧虑的。就在今天的这样一份源自实战团队呈现的完整指南,说不定能够给这样的一股热潮添入更多的理性思索。

训练成本全景解析
用于训练大模型的实际开销远远超过硬件投入,该团队在运用384块H100 GPU对3B参数模型进行训练之际发现,从数据准备这一环节开始一直到服务部署的整个流程成本是硬件成本的3至5倍,其中数据清洗并且标注占据总预算的35%,而持续运维之中的电力以及冷却费用在六个月的长时间训练周期下累计达到硬件采购成本的18%。
在特定具体案例当中,有一家金融科技公司,于2023年将2亿元投入到训练专用模型方面,然而却因为没有对部署成本进行预估,进而使得项目陷入搁浅状态。该团队所建立的成本模型表明,基础设施搭建仅仅占据28%,可是数据工程占有42%,模型优化占据30%,这样一种成本结构把“算力即核心”的传统认知给打破了。
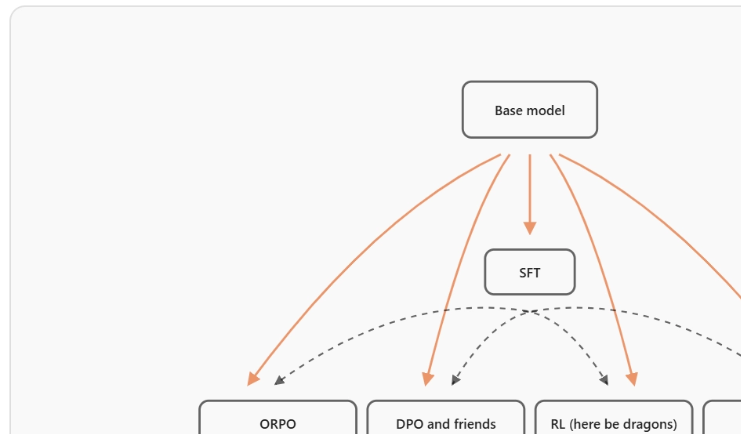
架构选择关键指标

团队针对 Llama、Qwen、Gemma 这三大架构,在相同硬件配置情形下的表现做了对比。在 3B 那种参数规模时,Qwen 在代码任务方面,MMLU 得分达到 68.2 。而且 Llama 在推理任务 GSM8K 上,准确率为 71.5% 。然而最终选定 Qwen 架构, 是由于其训练稳定性相对 Gemma 而言要高出 23% ,并且推理的时候内存占用减少了 18% 。
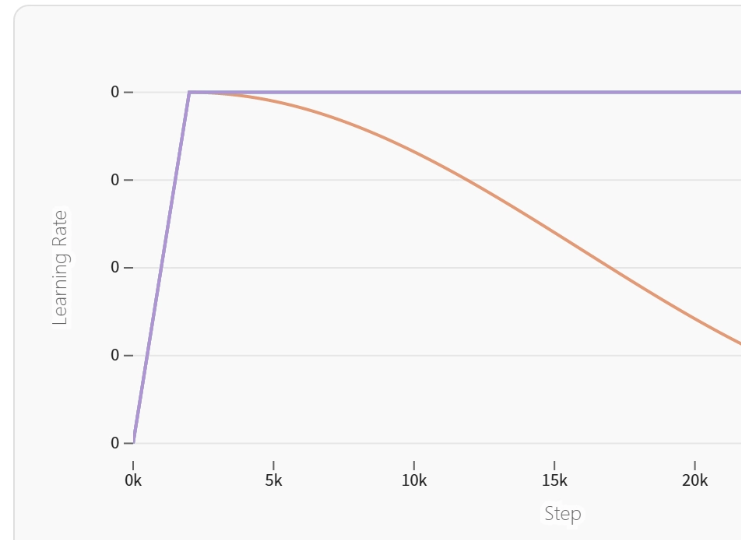
扩展性测试有所发现,参数从1B增加到3B之际,某些架构需重新调整学习率调度策略。团队借助监控损失曲面曲率变化,在训练早期便识别出潜在不稳定因素,这可为架构决策给出关键依据。
数据配方设计原则
针对数据质量评估体系,其涵盖着17个方向的检测指标。团队有所发觉,当未运用文档内掩码技术之际,模型于长文档理解任务里的准确率跌落了37%。经由施行法律文本的专项检验,他们构建起了数据清理的六步流程,把噪声数据比例由起初的15%降低到3%以下。
数据混合的比例,是借助严格的消融实验来确定的。当代码数据所占的比例,从百分之五提升到百分之十五的时候,模型的推理能力提升得十分显著,然而一旦超过百分之二十,就会致使常识推理能力下降。团队所开发的数据平衡算法,能够在训练的过程当中,动态地调整数据采样的权重。
训练过程监控体系
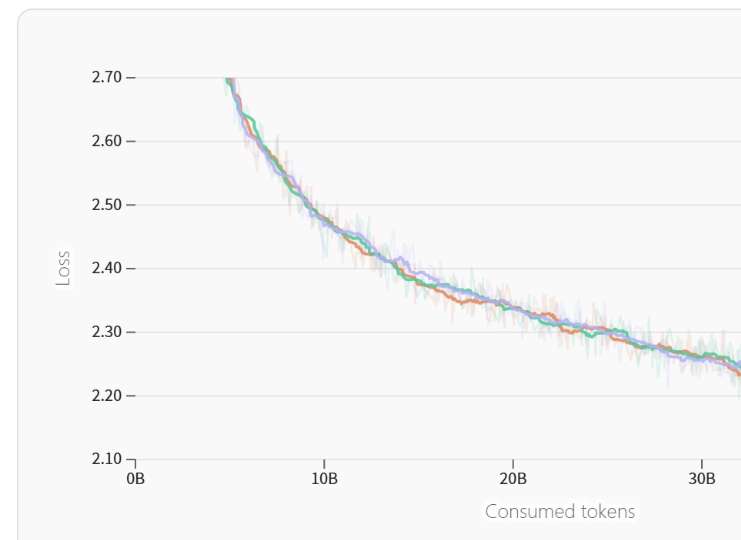
团队搭建起多层级的监控系统,自数据加载阶段开始至计算核心部分,都存在实时的指标情况。于最近一回的训练期间,该系统检查出GPU利用率出现异常的波动情形,经过仔细排查后发现,原来是网络带宽达到饱和状态,进而致使梯度同步出现延迟现象。凭借对AllReduce策略作出调整,训练的吞吐量回升了17% 。
早期的性能预测系统呢其是通过在训练进度达到1%那样的情况时插入探测任务,并且在训练进度达到5%的时候也插入探测任务,以及在训练进度达到10%之际还插入探测任务,如此这般就能提前去预测最终的性能,其准确率能够达到92% 。就是这样的这套系统在最近进行的项目当中帮助团队及时地放弃了两个效果不太理想的实验方向 ,进而节省了大约4000 GPU小时的计算资源 。
工程实践优化方案
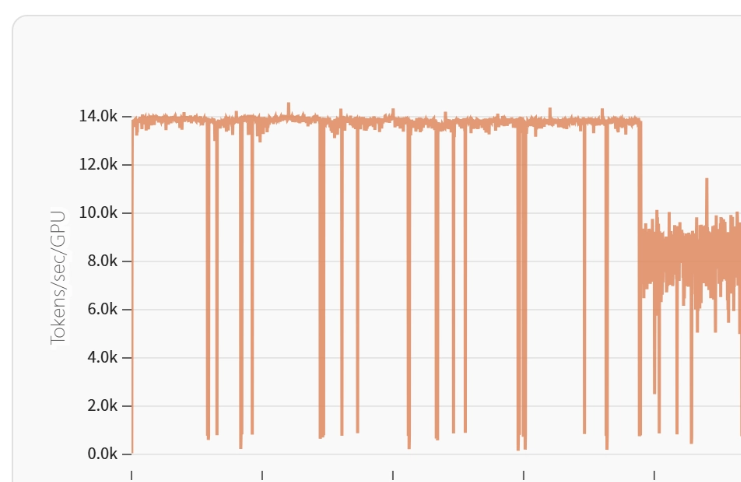
在基础设施方面,团队打造了弹性训练框架。在某次训练期间,某个计算节点出现NVLink故障,系统于35秒内达成计算任务迁移,确保了训练的连续性。检查点优化策略把保存间隔从2小时拉长至4小时,与此同时运用了差分保存技术,使得检查点写入时间降低了43%。
通信得到优化这方面,利用彼此重叠的计算跟通信操作,把梯度同步所需要的时间给隐藏掉了百分之六十五,该团队所开发出来的性能在进行分析操作的工具能够精准定位至具体的用来计算的核函数,在一次优化期间把LayerNorm操作的速度提高了百分之二十二 。
评估与应用对接
对于技术指标以及业务指标而言,是必须要实现对齐的。当团队针对法律领域的客户去定制模型之际,首先对现有的模型在法条理解、案例推理等等任务方面的表现展开了测试,在发现关键任务的准确率产生了差距,且该差距达到了28%之后,才启动了训练。上线的合同分析模型,在使得准确率提升了19%的同一时间,其推理速度达到了每秒15个请求。
构成奖励模型评估体系的,是包含8个维度的测试集,它能够精准地对偏好学习效果作出预测。于实际部署期间,借助A/B测试加以验证,经由此评估体系筛选而出的模型,在针对用户满意度的调查里,所得分数比运用传统方法时高出了31%。
对于各位开发者而言,在自行研发大模型的如此这般前行道路之上,你们觉得最容易遭受低估的那种隐性成本究竟是什么呢?欢迎来到评论区去分享你自己的具有实际操作意义的经验,要是感觉这篇文章具备一定帮助作用,请予以点赞给予支持并且分享给更多的同行们。



;){kind=link}
、成本分析、风险评估,区分探索性与验证性研究,并建立实验方法论(消融实验、早期评估)。在架构设计上,深入分析注意力机制与长上下文处理,通过实证比较GQA和RoPE等方案。数据管理方面,提出多阶段数据配方');){kind=link}
;){kind=link}
、成本分析、风险评估,区分探索性与验证性研究,并建立实验方法论(消融实验、早期评估)。在架构设计上,深入分析注意力机制与长上下文处理,通过实证比较GQA和RoPE等方案。数据管理方面,提出多阶段数据配方');){kind=link}