算力像水电!5分钟一键微调Qwen2-VL,再也不用写几千行代码
作者:佚名 时间:2025-12-14 14:52
作为一个 AI 开发者,你一定经历过这样的绝望时刻: 兴致勃勃地下载了最新的 Qwen2-VL 权重,准备用自己的垂直领域数据跑一次 SFT(监督微调)。然而,现实却是残酷的——
技术的进步本该是为了释放创造力,而不是增加门槛。在 Serverless 时代,算力应该像水电一样,扭开水龙头就有,关上就停,按需付费。
今天,我们将打破“微调=昂贵+麻烦”的刻板印象。不需要囤积显卡,也不需要精通运维,我们将带你体验一套“DevPod + Llama-Factory的极速组合拳”。
一、方案揭秘:FC + Llama-Factory 的“黄金搭档”
工欲善其事,必先利其器。在开始实战之前,让我们先拆解一下这套“开箱即用”的微调流水线背后的三位主角。当它们在 Serverless 架构下相遇,复杂的模型训练就变成了一场流畅的搭积木游戏。
1. 主角:Qwen VL 模型 —— 多模态领域的“六边形战士”
2. 工具:Llama-Factory —— 微调界的“瑞士军刀”
对于许多开发者来说,微调最大的门槛不是不懂原理,而是不想写那几千行的 PyTorch 训练代码。Llama-Factory 的出现,完美解决了这个问题。
3. 舞台:阿里云函数计算 FC —— 为 AI 而生的 Serverless 算力
有了好模型和好工具,我们还需要一个能跑得动它们的“舞台”。传统的 GPU 服务器租赁模式往往面临“部署难、闲置贵”的尴尬,而 函数计算 FC 给出了全新的解法:
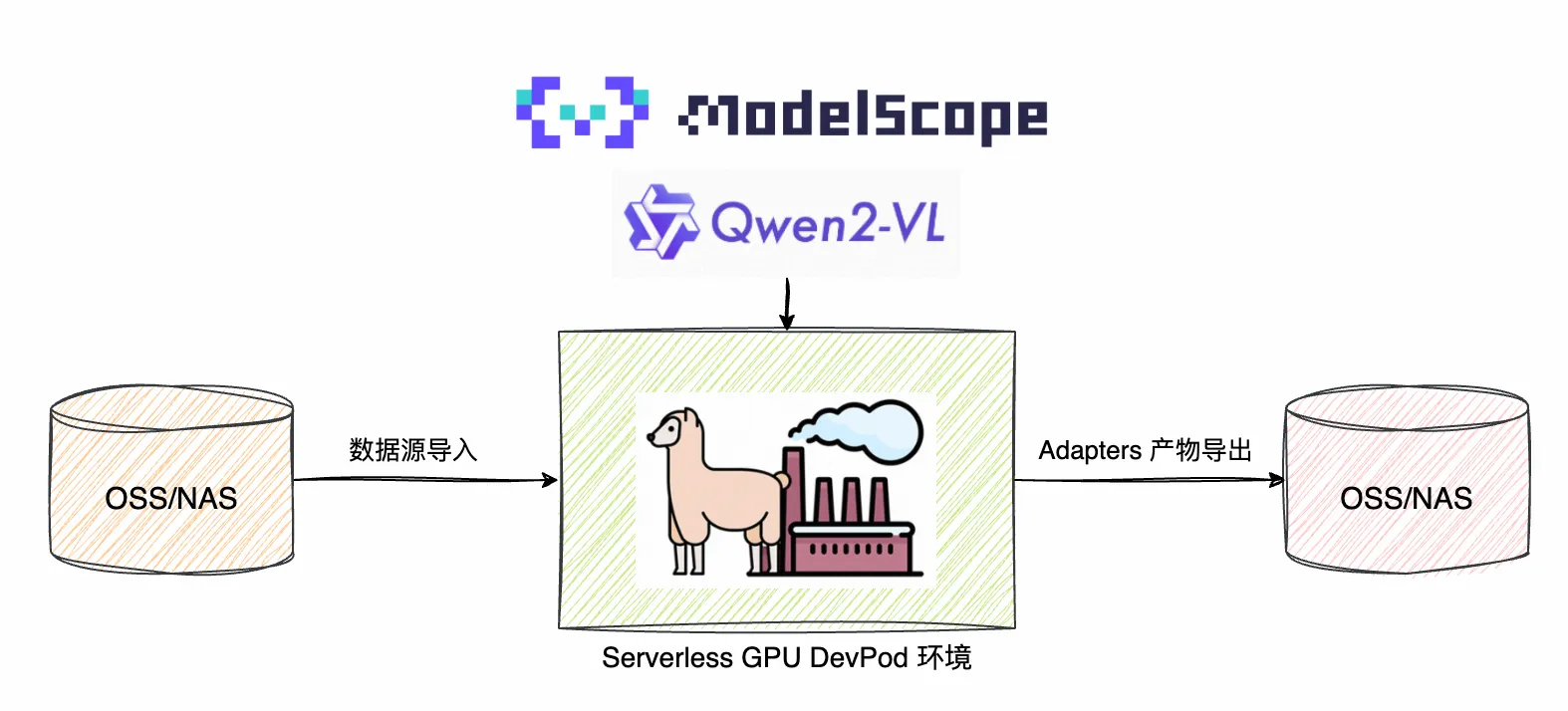
“当 Llama-Factory 的可视化交互遇上 FC 的极致弹性,微调 Qwen2-VL 就变成了一场‘点击即得’的流畅体验。我们不再需要像运维工程师一样盯着黑底白字的终端窗口,而是可以像修图师一样,在 Web 界面上优雅地打磨我们的模型。”
二、极速部署:5分钟搭建微调流水线
传统微调的第一步通常是“租服务器、装驱动、配环境”,而在 Serverless 架构下,我们直接从“应用”开始。
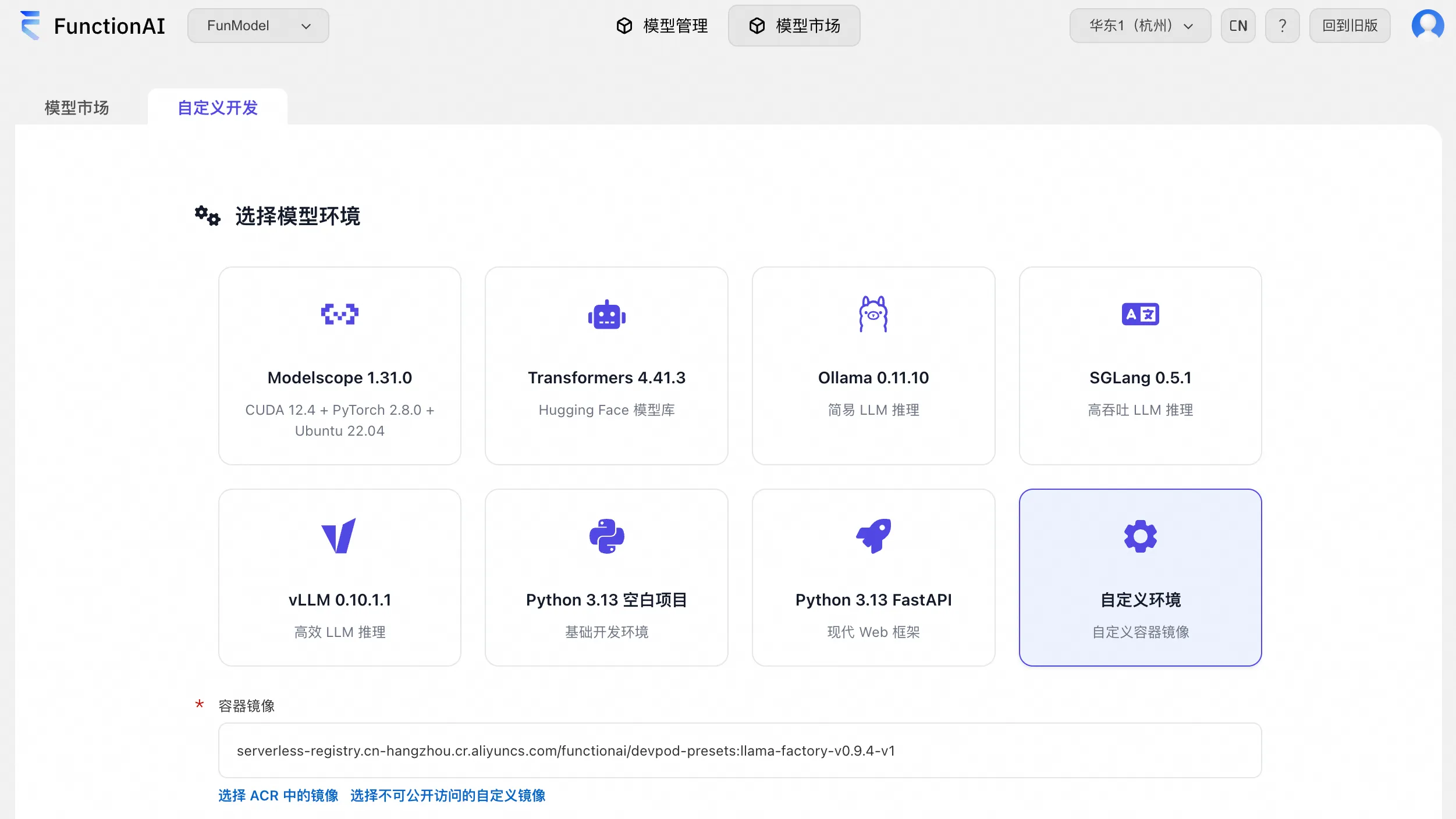
Step 1:DevPod 开发环境一键拉起
登录 Function AI 控制台 - FunModel - 模型市场,点击页面的「自定义开发」,在「模型环境下」选择「自定义环境」,在容器镜像地址中填入 serverless-registry.cn-hangzhou.cr.aliyuncs.com/functionai/devpod-presets:llama-factory-v0.9.4-v1。该镜像已内置 llama-factory v0.9.4 的版本。
Step 2:资源与存储配置(关键一步)
只需关注 GPU 类型。对于 Qwen3-VL 的 LoRA 微调,推荐选择 GPU 性能型单卡即可满足需求,性价比极高。
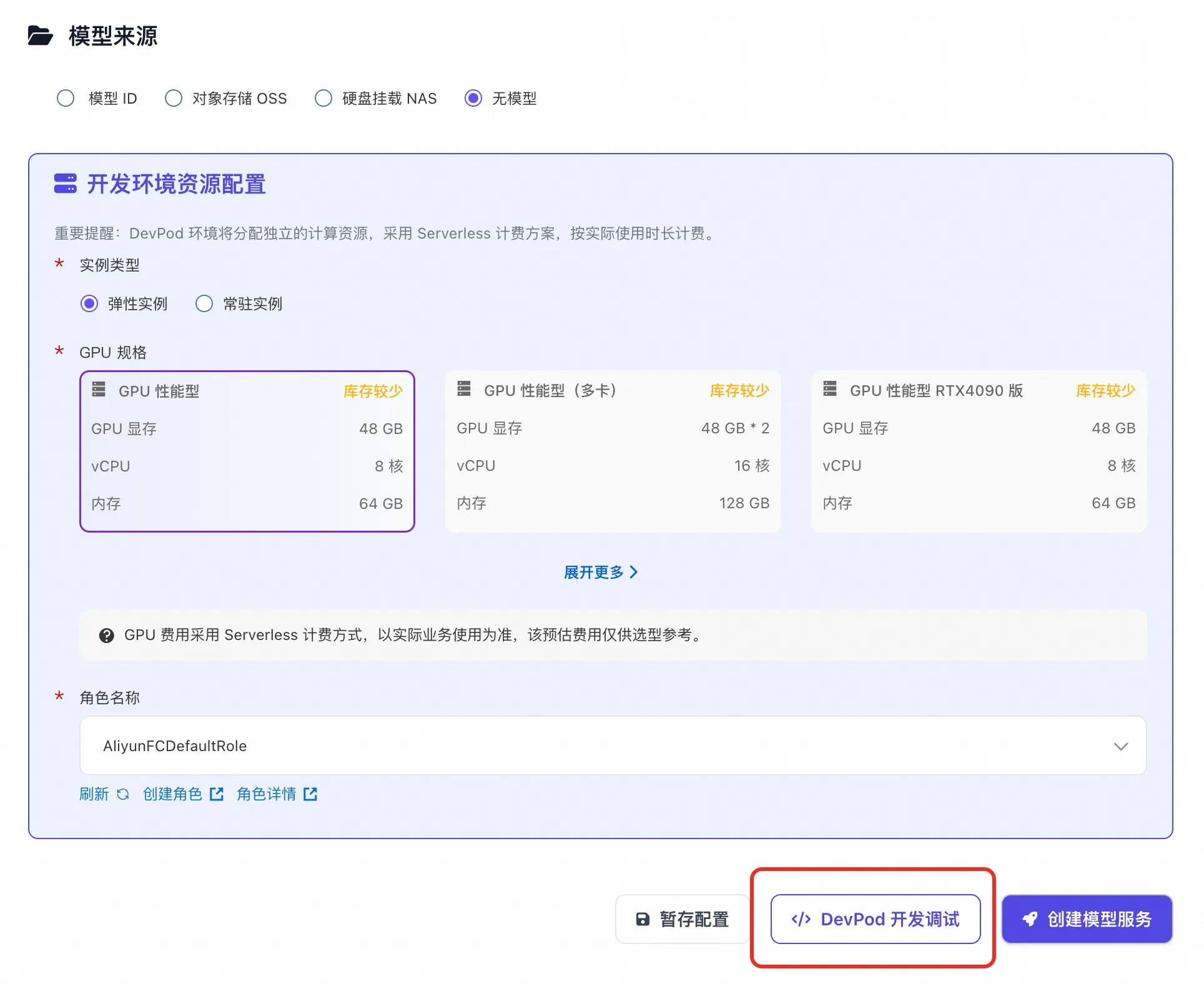
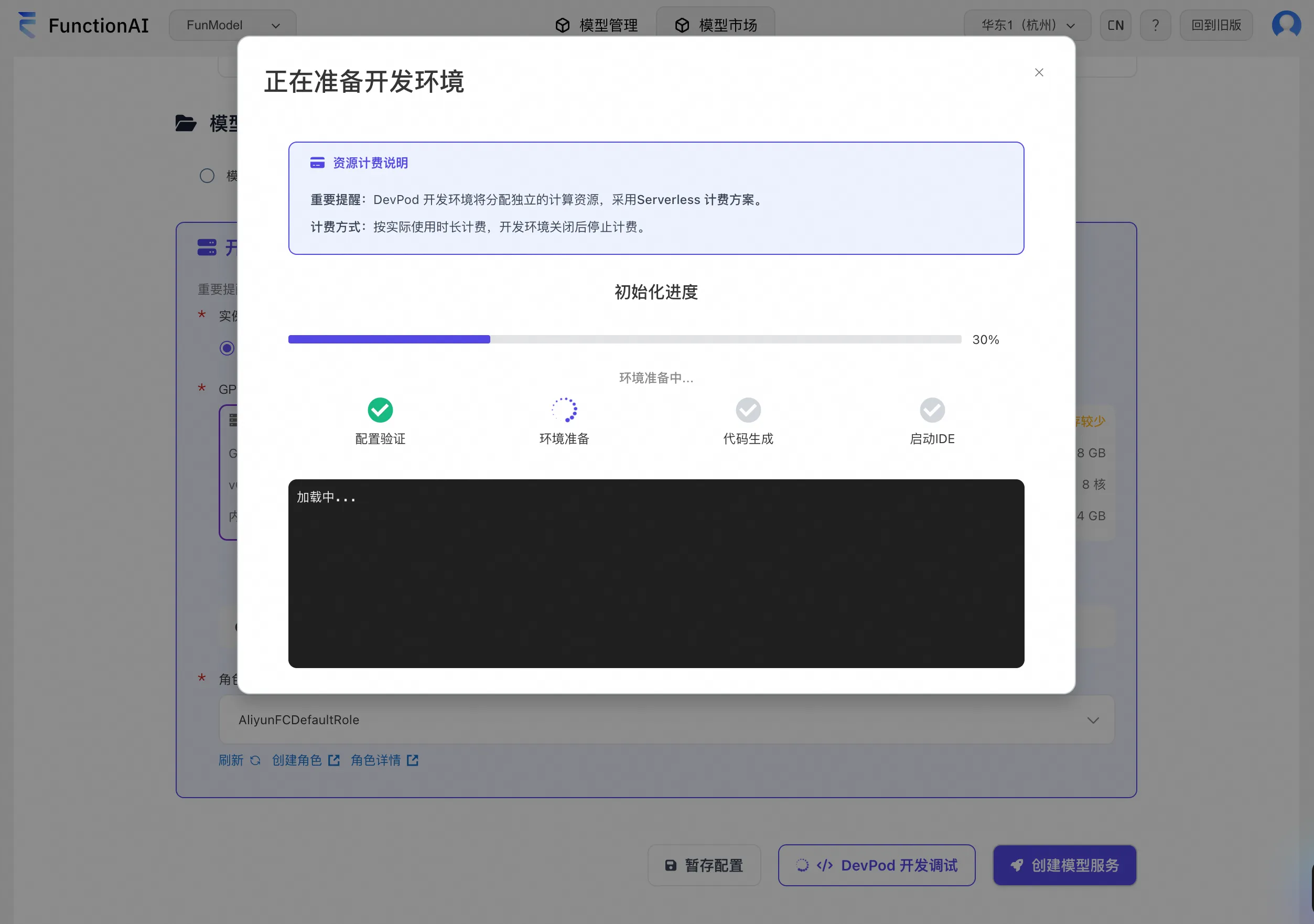
Step 3:一键拉起环境,点击「DevPod 开发调试」
FC 会自动拉取包含 CUDA 环境和 Llama-Factory 框架的镜像。大约等待 1-3 分钟,页面自动跳转到 DevPod 页面,我们进入 Terminal 下,执行命令 USE_MODELSCOPE_HUB=1 lmf webui 启动 llama-factory 的进程。
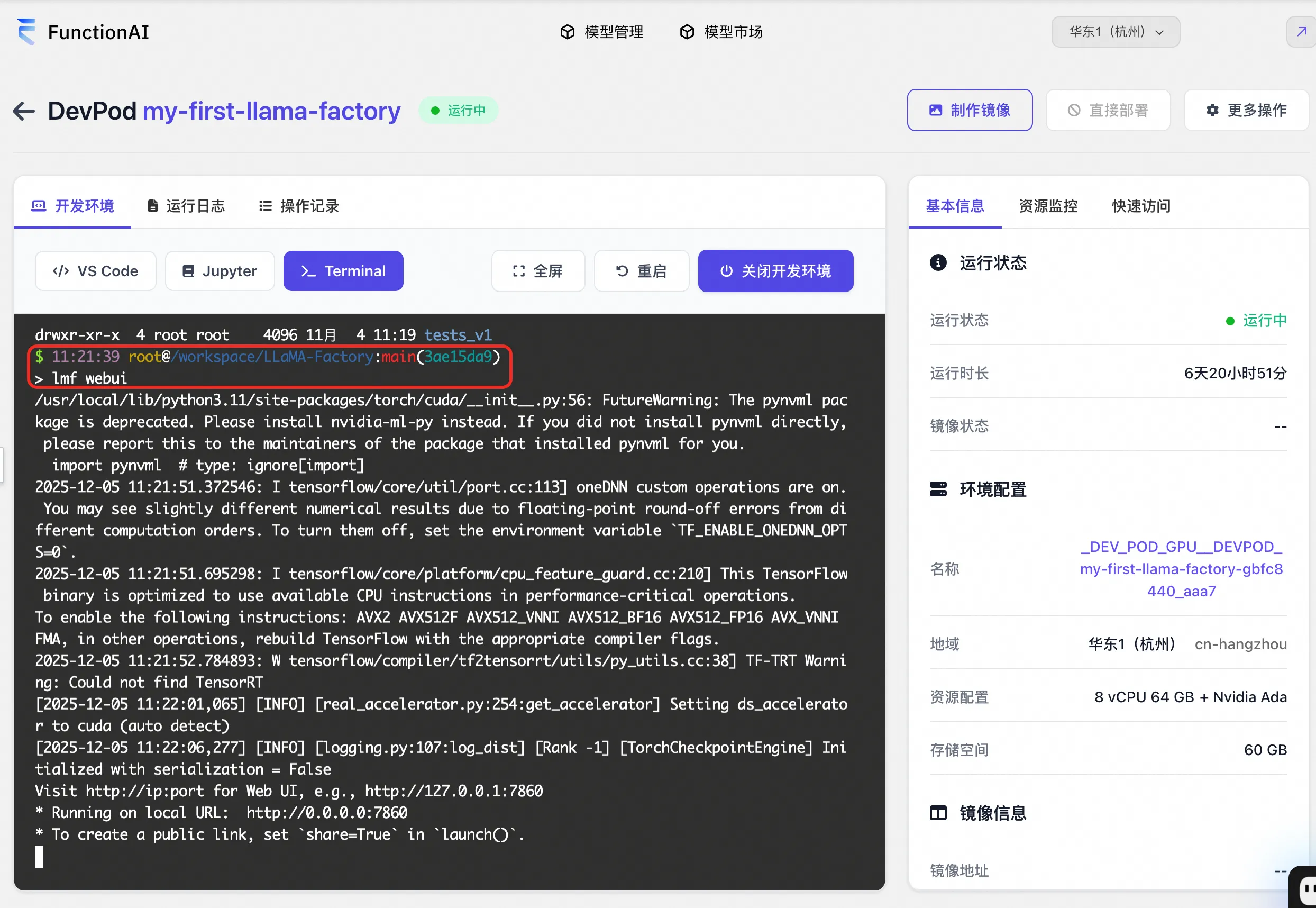
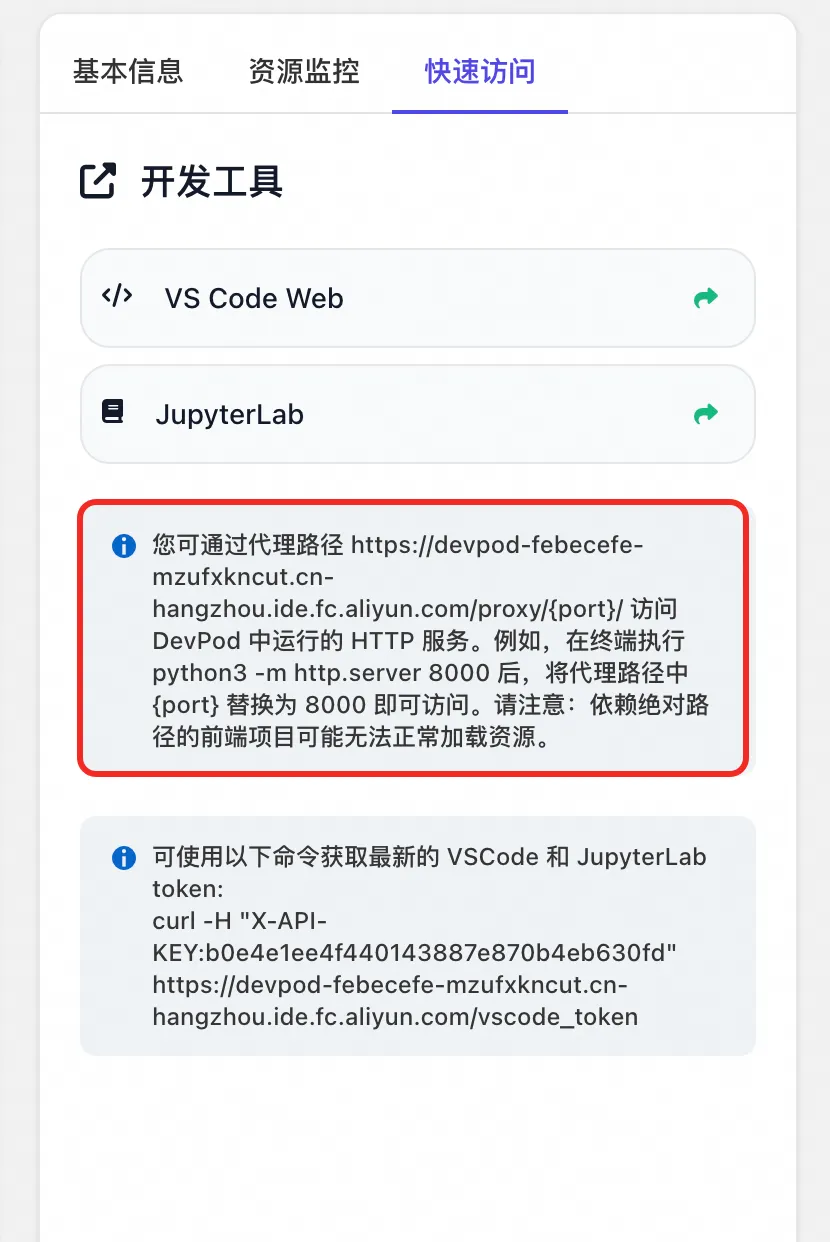
根据「快速访问」页签的提示,将 uri 中的 {port} 替换为 7860 即可(llama-factory 默认使用 7860 端口)。直接使用该 uri 在浏览器进行访问,进入 llama-factory 的 webui 界面。
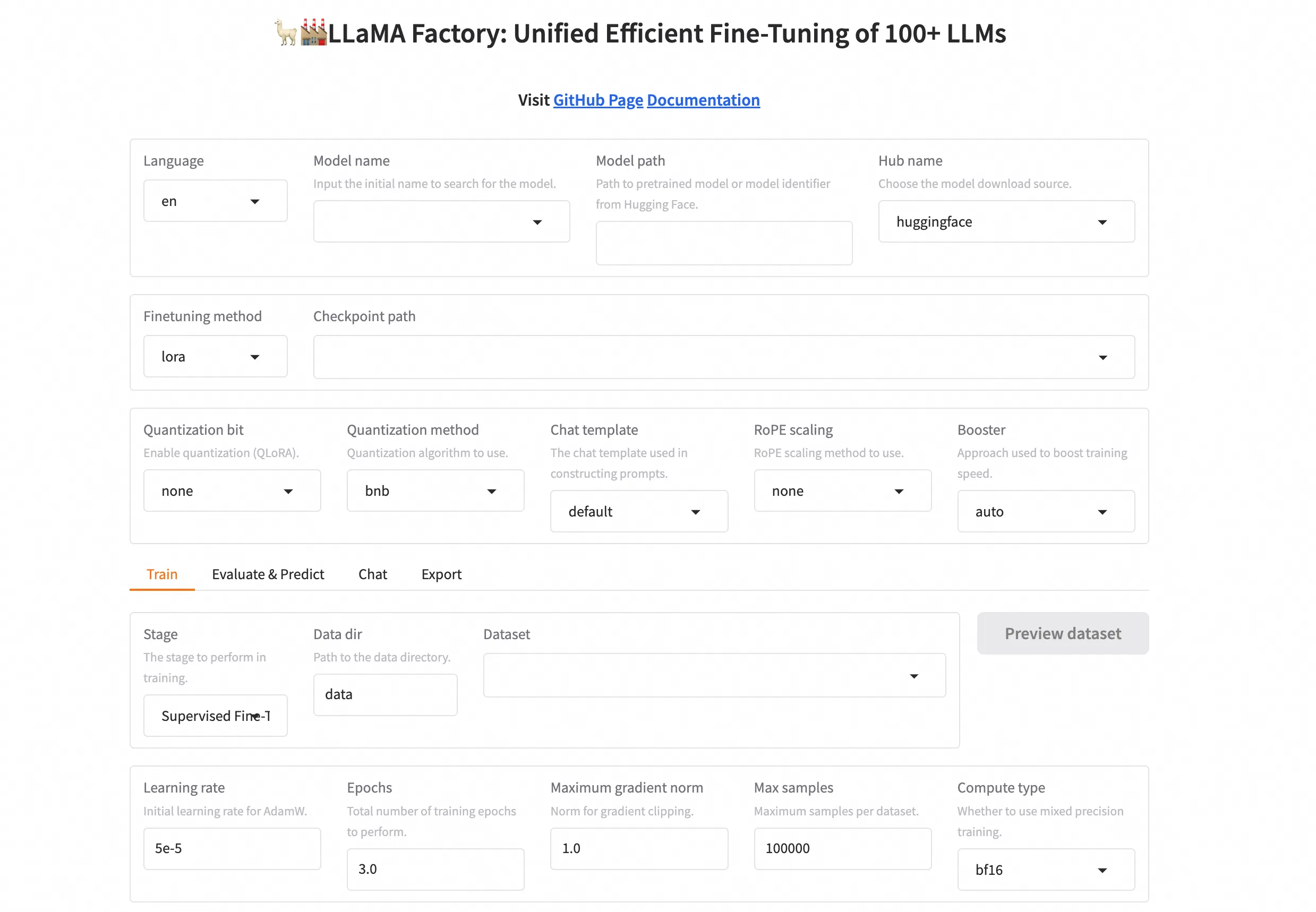
三、实战 SFT:像 P 图一样简单地微调模型
打开 WebUI 界面,你会发现微调大模型并不比使用 Photoshop 复杂多少。我们不需要敲一行 Python 代码,只需在面板上进行“勾选”和“填空”。
Step 1:模型与数据准备
Step 2:参数配置(LoRA大法好)
为了在 Serverless 环境下高效微调,我们采用 LoRA (Low-Rank Adaptation) 技术。它只训练模型的一小部分参数,却能达到惊人的效果。
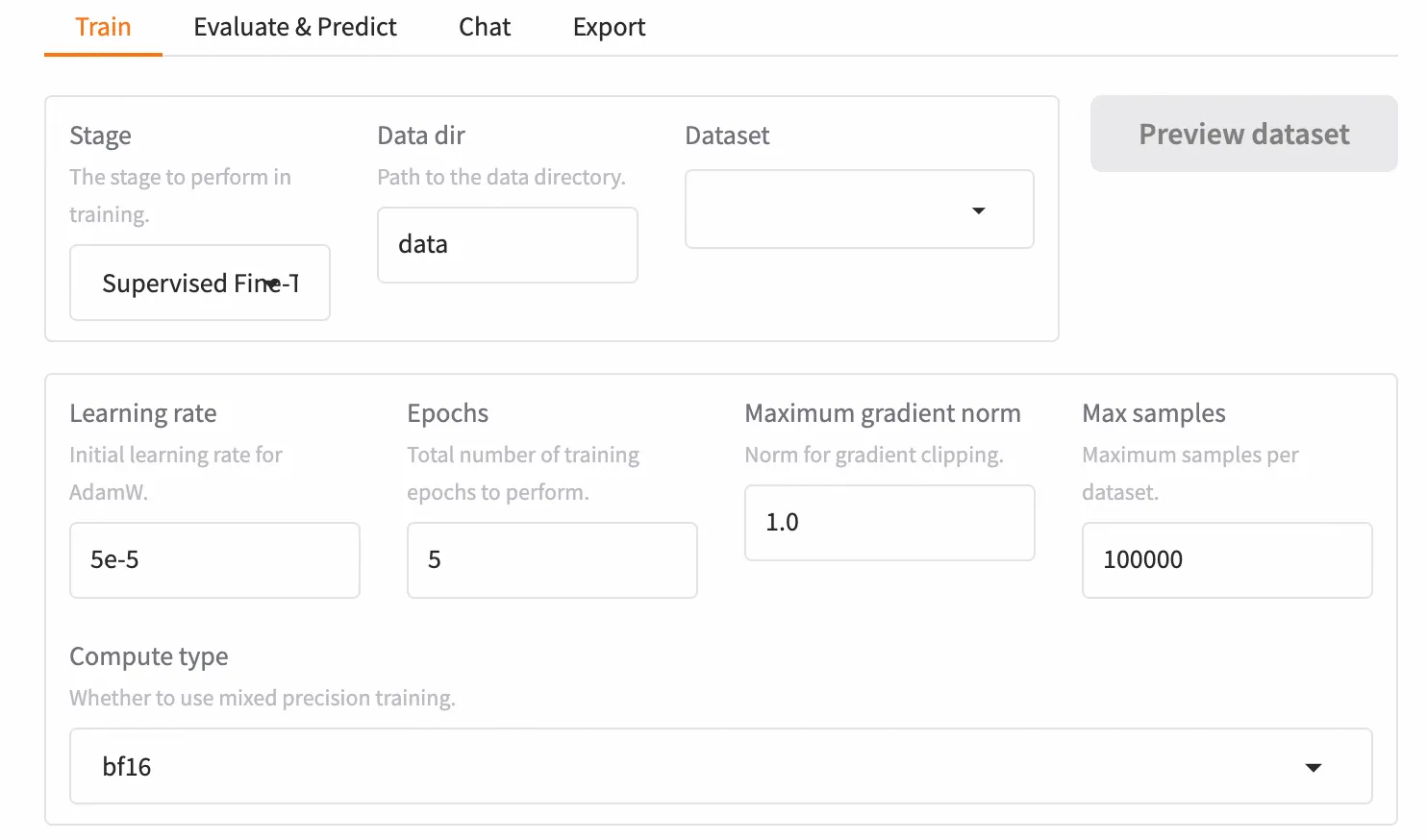
Step 3:启动训练与监控
一切就绪,点击鲜艳的 “开始训练” 按钮。 界面下方会自动弹出日志窗口和 Loss(损失)曲线图。看着 Loss 曲线像滑梯一样稳步下降,代表模型正在努力学习你教给它的新知识。
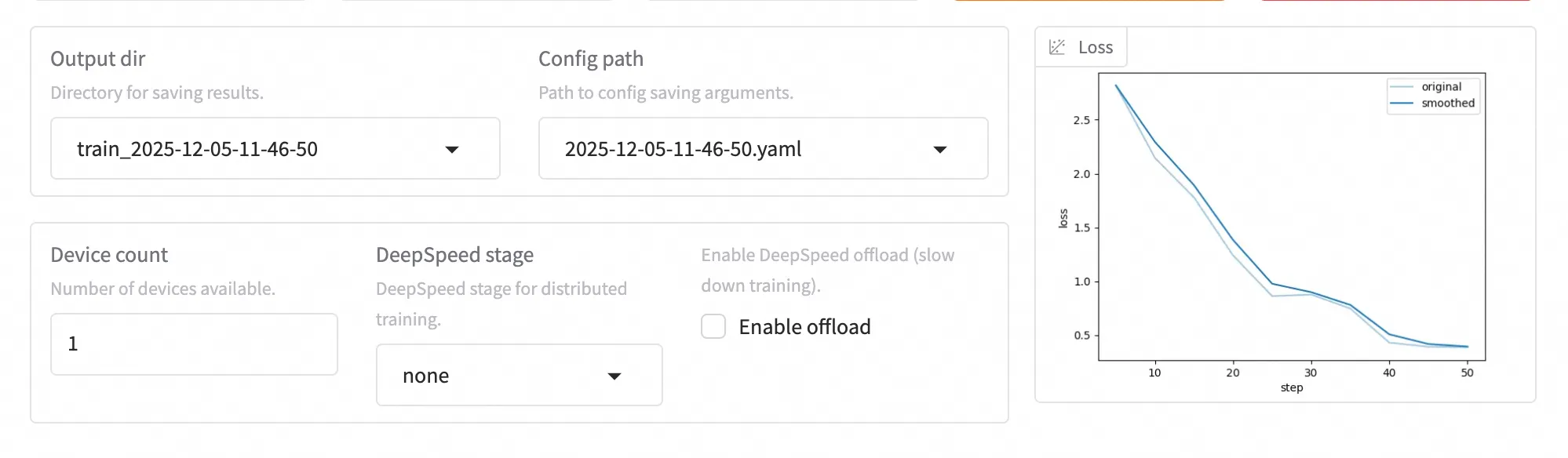
四、效果验证与模型导出:见证“专家”诞生
看着 Loss 曲线收敛只是第一步,真正的考验在于:它真的变聪明了吗?Llama-Factory 贴心地集成了评估与推理模块,让我们能即时验收成果。
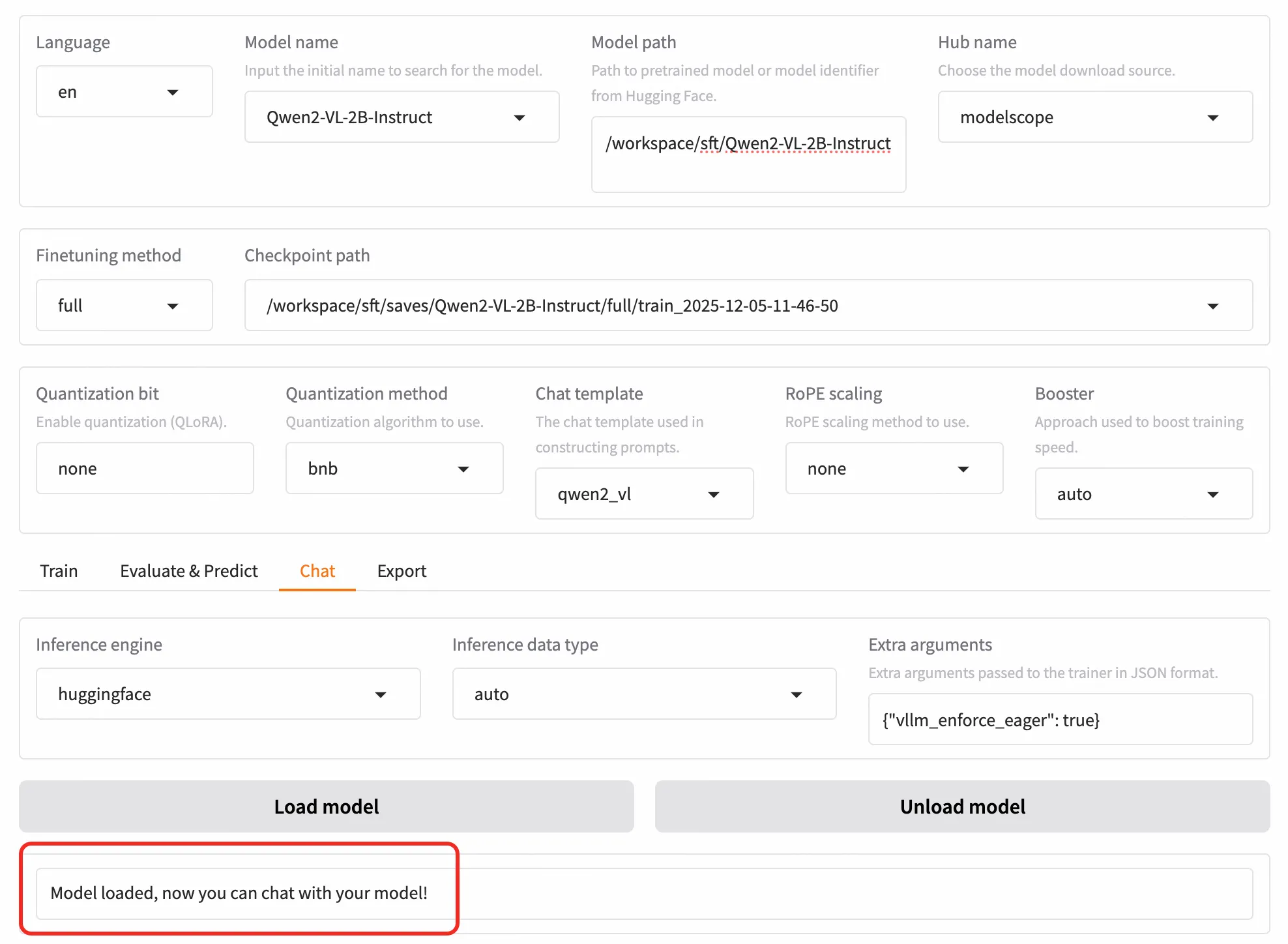
Step 1:Chat 页签在线推理
训练完成后,无需重启服务,直接点击 WebUI 顶部的 “Chat” 页签。
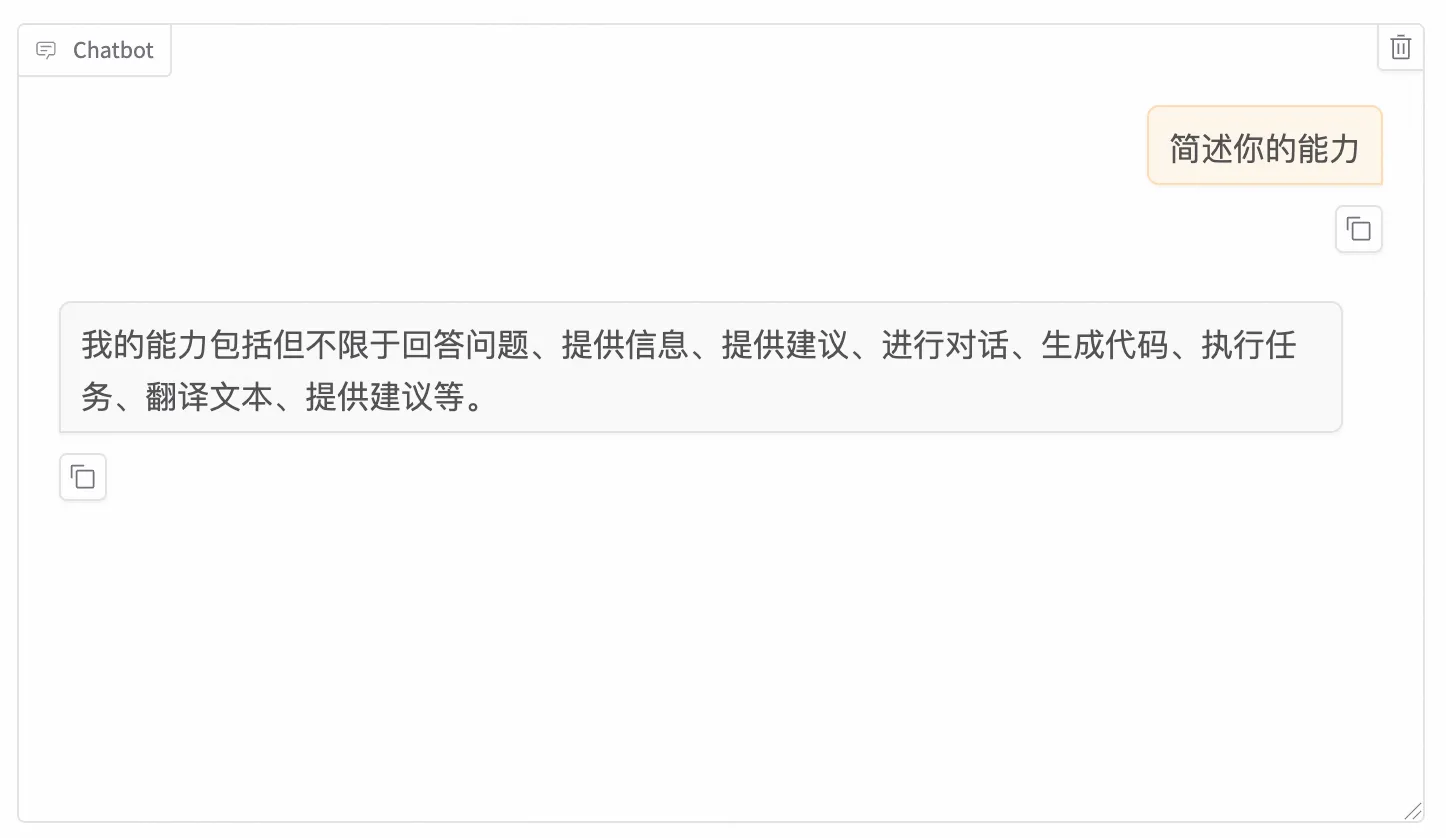
Step 2:微调前后效果“大比武”
为了验证效果,我们上传一张特定业务场景的图片(例如一张复杂的报销单据),并输入同样的 Prompt:“请提取图中的关键信息”。
微调前:
微调后:
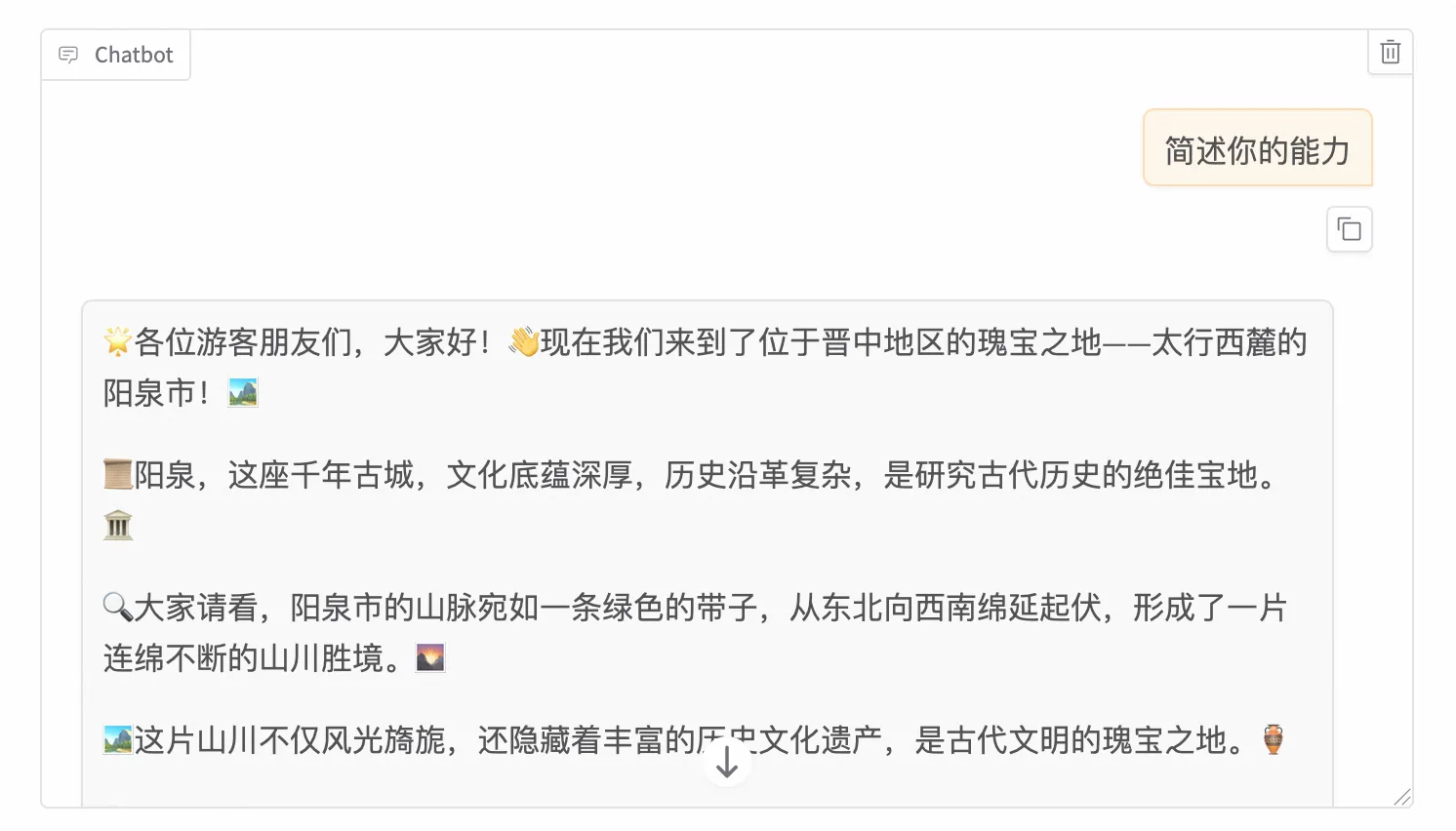
这就是 SFT 的魔力——让通用的天才变成垂直领域的专家。
Step 3:模型导出与落地
验证满意后,点击 “Export” 页签。
五、结语:Serverless AI,让创新触手可及
至此,我们只用了一杯咖啡的时间,就完成了从环境搭建、模型微调到效果验证的全流程。
最后,让我们算一笔账: 如果你为了这次实验去租赁一台 L20 服务器,通常需要按月付费,成本可能高达数千元,且大部分时间显卡都在空转。 而在阿里云函数计算(FC)上,你只需要为训练的那 2 小时 付费。按量付费,用完即走,成本可能不到一杯奶茶钱。
Serverless GPU 的核心价值,不仅仅是省钱,更是“解放”。 它把开发者从繁琐的运维泥潭中解放出来,不再需要担心 CUDA 版本、显存溢出或资源闲置。你只需要关注最核心的资产——数据与创意。
多模态的时代已经到来,Qwen2-VL 的大门已经敞开。 现在,轮到你了。
了解函数计算模型服务 FunModel
FunModel 是一个面向 AI 模型开发、部署与运维的全生命周期管理平台。您只需提供模型文件(例如来自 ModelScope、Hugging Face 等社区的模型仓库),即可利用 FunModel 的自动化工具快速完成模型服务的封装与部署,并获得可直接调用的推理 API。平台在设计上旨在提升资源使用效率并简化开发部署流程。
FunModel 依托 Serverless + GPU,天然提供了简单,轻量,0 门槛的模型集成方案,给个人开发者良好的玩转模型的体验,也让企业级开发者快速高效的部署、运维和迭代模型。
在阿里云 FunModel 平台,开发者可以做到:
技术优势
特性 FunModel 实现机制 说明
资源利用率
采用 GPU 虚拟化与资源池化技术。
该设计允许多个任务共享底层硬件资源,旨在提高计算资源的整体使用效率。
实例就绪时间
基于快照技术的状态恢复机制。
实例启动时,可通过快照在毫秒级别恢复运行状态,从而将实例从创建到就绪的时间控制在秒级。
弹性扩容响应
结合预热资源池与快速实例恢复能力。
当负载增加时,系统可以从预热资源池中快速调度并启动新实例,实现秒级的水平扩展响应。
自动化部署耗时
提供可一键触发的构建与部署流程。
一次标准的部署流程(从代码提交到服务上线)通常可在 10 分钟内完成。
更多内容请参考
- 模型服务FunModel 产品文档
- FunModel快速入门
- FunModel 自定义部署
- FunModel 模型广场




;){kind=link}
和Llama-Factory组合进行Qwen2-VL模型微调的方案。该方案无需大量显卡或运维知识,通过DevPod一键拉起环境,利用Llama-Factory的WebUI进行可视化微调,实现5分钟搭建流水线。文中详细阐述了模型准备、参数配置、训练监控、效果验证及模型导出等步骤,突出了Serverless架构下算力按需付费的优势,');){kind=link}
;){kind=link}
和Llama-Factory组合进行Qwen2-VL模型微调的方案。该方案无需大量显卡或运维知识,通过DevPod一键拉起环境,利用Llama-Factory的WebUI进行可视化微调,实现5分钟搭建流水线。文中详细阐述了模型准备、参数配置、训练监控、效果验证及模型导出等步骤,突出了Serverless架构下算力按需付费的优势,');){kind=link}