连续创业者Naveen Rao再出发!要让AI计算能效提高1000倍
作者:佚名 时间:2025-12-21 09:54
一位长期致力于神经学与计算机学科交叉处的连续创业者,在连续两家创业公司成功退出后,再次投身创业。
面对现在AI领域以GPU为核心的计算范式能效低,能耗高企的现状,他想打造具备“生物级别能效”的计算系统,跳出冯·诺依曼架构的计算机架构,让AI计算的能效提高1000倍。
这位叫Naveen Rao的创业者,与三位经验丰富的联合创始人一起创立了初创公司Unconventional AI,并获得由Lightspeed和Andreessen Horowitz领投的4.75亿美元的种子轮融资,Sequoia Capital、Lux Capital、DCVC、Future Ventures、Jeff Bezos等顶尖投资机构和投资人参投, Naveen Rao个人也投资1000万美元,公司目前估值达到45亿美元。
跳出冯·诺依曼计算架构,让AI计算系统能效提高1000倍
Unconventional AI由Naveen Rao (CEO)与MeeLan Lee、Sara Achour(斯坦福大学助理教授)、Michael Carbin(麻省理工学院副教授)联合创立。

Unconventional AI的创始团队,图片来源:Unconventional AI
Naveen Rao此前曾有两次成功的创业退出经历(Nervana被Intel以4亿美元收购,Mosaic ML被Databricks以13亿美元收购),他是少数能同时深刻理解人工智能硬件和软件两端的专家之一。
MeeLan在Google、Qualcomm和Intel拥有数十年的模拟电路设计经验。Sara Achour和Michael Carbin分别是斯坦福大学和麻省理工学院的顶尖研究学者,在为新型计算基底(如模拟器件、量子系统、神经形态架构)编程方面拥有深厚的专业知识。
过去半个世纪,在摩尔定律的推动下,计算成本持续下降。每一次成本的降低都扩展了计算机的应用范围,从最初的科研,一直到商业工具、游戏和娱乐领域。
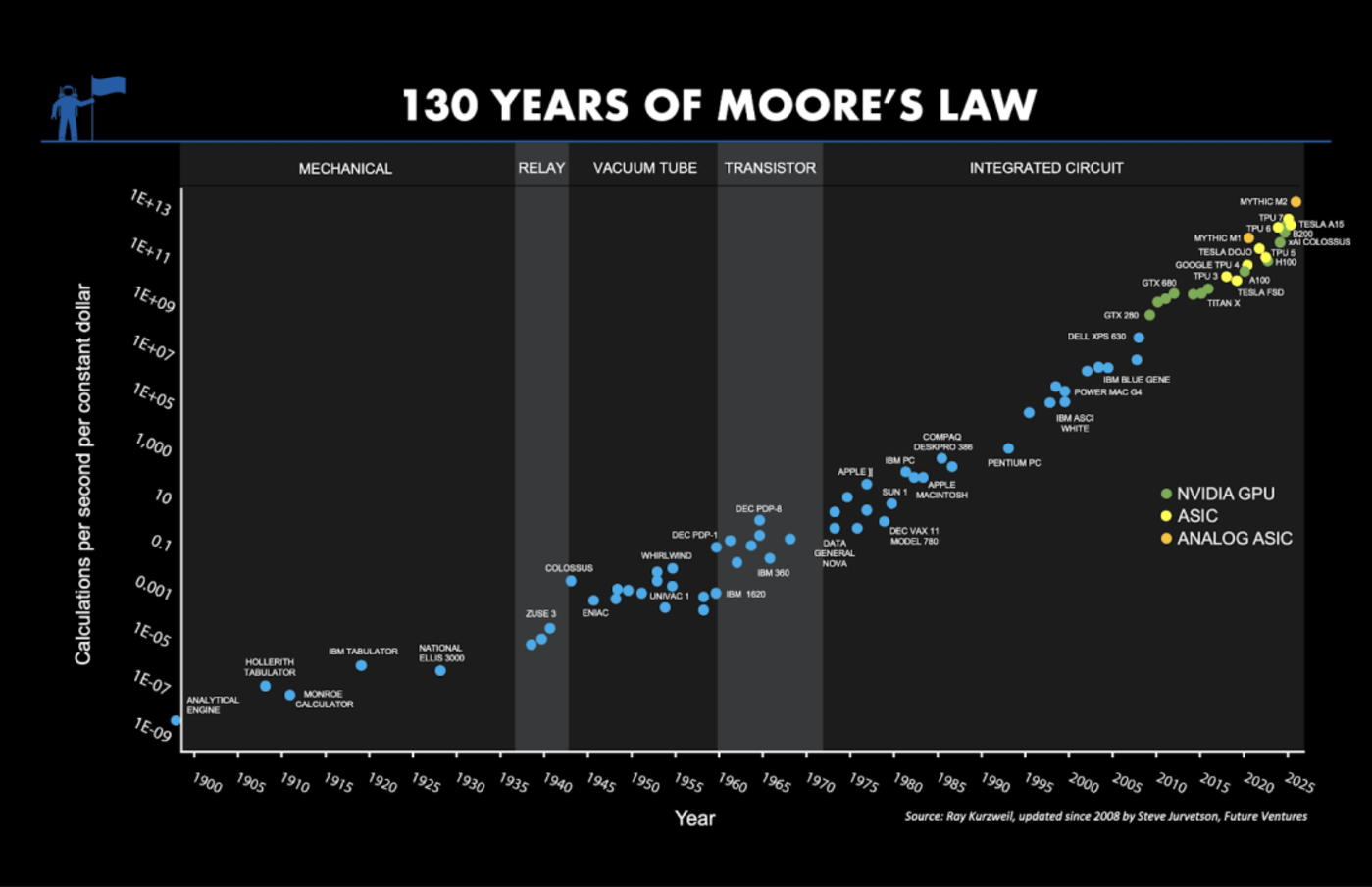
持续了很多年的摩尔定律,图片来源:Unconventional AI
在人工智能领域,也有类似现象,一个AI模型的训练和服务成本,每年会降至原来的四分之一(这个速度是摩尔定律的十倍),这也将非常有助于人工智能的普及。
如今,GPU是人工智能产业的支柱,绝大多数的模型训练和推理工作负载都由它们承担。AI应用越来越广泛,对算力需求将以前所未有的速度激增,前沿AI模型的训练已经需要数万甚至数十万块GPU。推理的算力需求则将是训练的十倍以上,曾经被视为天方夜谭的、超过1吉瓦 (gigawatt) 的新建算力中心,如今已是家常便饭。
AI算力中心,需要巨量的电力,让很多地方的电力供应捉襟见肘。在未来3到4年内,全球能源供应将成为计算能力发展的瓶颈。一种更高能效,耗能更少的AI计算能力,成为了AI持续进展的必须。
作为人工智能底层的技术,神经网络本身就来源于大脑,多位AI领域的顶尖人物,例如两位诺奖获得者Geoffrey Hinton和Demis Hassabis就具有神经学的背景;Yoshua Bengio和Yann LeCun也都深入研究过生物系统。
同样是神经学背景的Naveen Rao在大学时代就钻研大脑和神经系统内部的计算,和导师一起用模拟电路,从电气角度去模仿神经元的行为。他表示,自己内心真正的热爱,始终在于“如何让机器变得智能”。
他的第一次创业(Nervana)就是打造“软硬一体”的神经网络加速方案:专为训练深度网络设计的芯片。在Unconventional AI的这一次创业,他要继续这个方向,并且走得更远。
他的核心洞察是:人工智能模型是概率性的,而用于训练和运行它们的芯片却并非如此。
神经网络的运行方式类似于一台随机机器。当它在基于经典冯·诺依曼架构的数字计算机上实现时,运行于确定性的抽象层之上,而底层执行的,是那些为模拟数字行为而精确调校的模拟电路,这种方式导致了大量的效率损耗。
NVIDIA最新的GPU,单块功耗就超过1000瓦,现在实际上是以牺牲能效为代价,换取算力和成本的规模化。与此同时,作为神经网络的最初原型,人类大脑的运行功耗仅为20瓦。
既然神经网络实际上是一台随机机器。那么,为何要用一种高度精确且确定性的基底,去运行一个本质上是随机且分布式的系统呢?
事实上,Unconventional AI正在设计专为人工智能这类概率性工作负载而生的新型计算系统。这种想法有些类似于模拟计算系统,最早的计算机,其实就是模拟计算机,但是当时它因为采用电子管计算,遇到了规模化难题(耗能太高,体积太大),于是人们转向了数字化,用晶体管来计算。
但模拟计算在本质上仍然更高效,因为它实际上是一种“类比计算”。例如:我能否构建一个物理系统,使其与我试图表达或计算的量相似?
Unconventional AI将直接利用物理定律本身来运行神经网络,而不是去模拟某个物理系统。
这类系统的功耗在理论上可以比数字计算机低千倍之多,Unconventional AI的终极目标,是实现生物学尺度的能效。
这是从第一性原理出发,对计算模型、物理抽象乃至物理实现进行的全盘重新思考。大多数人工智能硬件公司都聚焦于微架构或指令集的优化,Unconventional AI正在进行更深层次的探索。
它计划用五年时间来打造一款全新的模拟芯片。创始人Naveen Rao表示,他们将与台积电 (TSMC) 合作,其首款原型“可能会成为有史以来最大尺寸的模拟芯片之一。”
那么这个模拟芯片要怎么去研发?
Naveen Rao表示,Unconventional AI将效仿F1车队提升赛车空气动力学性能的方式:在一个“硅风洞”中,构建一个“生物学尺度”的智能层模型,从而实现计算效率的提升。
因为某种意义上,风洞就是绝佳的模拟计算机例子,比如我们有一辆赛车,想了解气流是如何绕过它的。理论上,可以通过计算来解决这些问题,但问题在于计算结果总会有偏差,很难知道真实系统会是什么样子。而且要通过计算流体动力学进行精确模拟也非常困难,所以人们至今仍在建造风洞。这实际上就是在建模,它就是一台模拟计算机。
当然,对于要探索全新计算范式的公司来说,现在它们甚至都没有产品,它们现在做的大部分工作,还是理论研究,是从第一性原理出发,探究学习过程如何在物理系统中发生。
Unconventional AI并非唯一致力于模拟计算的公司。创业公司Mythic一直在开发其模拟处理器,并声称其芯片的性能比传统的CPU、GPU和TPU高出一个数量级。该芯片正被用于边缘人工智能场景,例如无人机、机器人和智慧城市部署。
也有中国的研究团队在探索模拟芯片,北京大学的研究人员构建了一个模拟矩阵计算 (AMC) 系统,他们在论文里证明,这款芯片的性能可超越NVIDIA GPU达 1000倍,而能耗仅为其百分之一。
为什么这么多创业者要颠覆NVIDIA建立的CUDA生态?
GPU确实很适合AI的计算,CUDA生态也很牢靠,所以作为人工智能产业的基石,它的市值能够达到4万亿美元。但人工智能工作负载的同质性,使其非常适合采用专用计算硬件,而需求的巨大规模,则让其他公司不断投入创新,试图颠覆它。
Google的TPU,就已经初见成效,它迭代到了TPU V7,现在Google的SOTA模型Gemini 3,就是在这个计算系统上训练和推理。Meta和Anthropic都与Google签订了规模达百亿美元的购买或算力租赁协议。
在TPU之外,一票创业公司也试图颠覆CUDA生态,例如Groq的LPU,这家公司已经获得15亿以上的融资,达到了69亿美元的估值。
还有芯片设计里的顶尖专家Jim Keller(他设计了苹果的A5处理器和AMD的Zen架构),他参与的创业公司Tenstorrent以RISC-V CPU为技术路线做AI芯片,目前已经累计融资超10亿美元。以及以光子计算为技术路线的Lightmatter,它获得8.5亿美元的累计融资。
不过这些企业的产品,大部分还是在经典冯·诺依曼架构内,Unconventional AI做的事情则更加底层,虽然很早期,很不成熟,但一旦做成了,就可以颠覆现有的计算范式,为AI的广泛应用提供新的可能性,很有价值。
尽管现在硅谷看起来已经比较商业,但硅谷精神的底层,仍然是创新驱动和技术驱动的,Unconventional AI的创始人Naveen Rao就是很有硅谷精神的人,所以他敢于推翻现有的计算系统范式。
中国的创业者,很多都是产品经理出身,擅长打造产品和应用;而近年来,也有越来越多的中国创业者有勇气也有能力去进行原创技术创新,从大疆、韶音到拓竹,影石,莫不如此。AI发展的下一步是物理AI,这是一个大的范式转变,我们希望看到越来越多敢于进行底层创新的创业者投身到这个大潮中去。




;){kind=link}
;){kind=link}
;){kind=link}
;){kind=link}